Матрица пользователя : weissuu
- Заполненных тем 6
- Заполненных навыков 46
- Data Arrays Javascript Frontend algoritm CSS
- 1109
- 2024-12-18 07:23:43
Hard skills
Пет проекты и сервисы
Объе́ктно ориенти́рованное программи́рование (сокр. ООП) — методология или стиль программирования на основе описания типов/моделей предметной области и их взаимодействия, представленных порождением из прототипов или как экземпляры классов, которые образуют иерархию наследования.
При создании программных систем использование принципов SOLID способствует созданию такой системы, которую будет легко поддерживать и расширять в течение долгого времени. Принципы SOLID — это руководства, которые также могут применяться во время работы над существующим программным обеспечением для его улучшения, например, для удаления «дурно пахнущего кода».
https://habr.com/ru/companies/dataart/articles/262817/
https://gist.github.com/zmts/802dc9c3510d79fd40f9dc38a12bccfc?permalink_comment_id=4823694
software development process or software development life cycle (SDLC)
https://ru.wikipedia.org/wiki/Процесс_разработки_программного_обеспечения
Design Patterns, описанные в книге "Банды четырех"
Шаблоны используемы в построении архитектуры
todo
https://ru.wikipedia.org/wiki/%D0%90%D0%BD%D1%82%D0%B8%D0%BF%D0%B0%D1%82%D1%82%D0%B5%D1%80%D0%BD
https://ru.wikipedia.org/wiki/%D0%90%D0%BD%D1%82%D0%B8%D0%BF%D0%B0%D1%82%D1%82%D0%B5%D1%80%D0%BD
https://ru.wikipedia.org/wiki/%D0%90%D0%BD%D1%82%D0%B8%D0%BF%D0%B0%D1%82%D1%82%D0%B5%D1%80%D0%BD
https://proglib.io/tests/proydi-test-na-znanie-algoritmov-i-struktur-dannyh
https://education.yandex.ru/handbook/algorithms https://apptractor.ru/info/articles/6-algoritmov-kotorye-dolzhen-znat-kazhdyy-razrabotchik.html https://codechick.io/tutorials/dsa/dsa-algorithm
-
Асимптотический анализ / Сложность
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Асимптотический анализ показывает порядок роста алгоритма - как увеличивается время работы алгоритма при увеличении объема входных данных. По факту измеряем не время, а число операций, например - сравнения,присваивания,выделение памяти. Обычно измеряется наихудший случай выполнения, если не оговорено иное. Записывается, как O(n) (О нотация, О большое) . Примеры:
Константный — O(1) Линейный — O(n) Логарифмический — O( log n) Линеарифметический — O(n·log n) Квадратичный — O(n 2) И другиеhttps://education.yandex.ru/handbook/algorithms/article/algoritmy-i-slozhnost
-
Динамическое программирование
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Динамическое программирование — способ решения сложных задач путём разбиения их на более простые подзадачи. Он применим к задачам с оптимальной подструктурой, выглядящим как набор перекрывающихся подзадач, сложность которых чуть меньше исходной. В этом случае время вычислений, по сравнению с «наивными» методами, можно значительно сократить.
Ключевая идея в динамическом программировании достаточно проста. Как правило, чтобы решить поставленную задачу, требуется решить отдельные части задачи (подзадачи), после чего объединить решения подзадач в одно общее решение. Часто многие из этих подзадач одинаковы. Подход динамического программирования состоит в том, чтобы решить каждую подзадачу только один раз, сократив тем самым количество вычислений. Это особенно полезно в случаях, когда число повторяющихся подзадач экспоненциально велико.
Метод динамического программирования сверху — это простое запоминание результатов решения тех подзадач, которые могут повторно встретиться в дальнейшем. Динамическое программирование снизу включает в себя переформулирование сложной задачи в виде рекурсивной последовательности более простых подзадач.
-
Рекурсия
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Рекурсия – это когда функция вызывает сама себя(напрямую или через функцию посредника), как правило, с другими аргументами. Рекурсия помогает писать код более компактно и понятно, однако имеет оверхэд по памяти из-за необходимости хранить стек вызова. Для оптимизации можно переписать алгоритм используя циклы - любая рекурсия может быть переделана в цикл, как правило, вариант с циклом будет эффективнее. Также есть хвостовая рекурсия.
Хвостовая рекурсия — частный случай рекурсии, при котором любой рекурсивный вызов является последней операцией перед возвратом из функции. Подобный вид рекурсии примечателен тем, что может быть легко заменён на итерацию путём формальной и гарантированно корректной перестройки кода функции. Оптимизация хвостовой рекурсии путём преобразования её в плоскую итерацию реализована во многих оптимизирующих компиляторах. В некоторых функциональных языках программирования спецификация гарантирует обязательную оптимизацию хвостовой рекурсии.
-
Разделяй и властвуй
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Разделяй и властвуй(divide and conquer) — важная парадигма разработки алгоритмов, заключающаяся в рекурсивном разбиении решаемой задачи на две или более подзадачи того же типа, но меньшего размера, и комбинировании их решений для получения ответа к исходной задаче; разбиения выполняются до тех пор, пока все подзадачи не окажутся элементарными.
Типичный пример — алгоритм сортировки слиянием. Чтобы отсортировать массив чисел по возрастанию, он разбивается на две равные части, каждая сортируется, затем отсортированные части сливаются в одну. Эта процедура применяется к каждой из частей до тех пор, пока сортируемая часть массива содержит хотя бы два элемента (чтобы можно было её разбить на две части).
Алгоритм стоит из 3 шагов:
- Разделяй. Разделяем задачу на подзадачи с помощью рекурсии.
- Властвуй. Как только задачи станут достаточно малы — рекурсивно решаем.
- Объединяй. Объединяем все подзадачи в одно целое, чтобы получить решение исходной задачи.
-
Жадный алгоритм
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Жадный алгоритм — алгоритм, заключающийся в принятии локально оптимальных решений на каждом этапе, допуская, что конечное решение также окажется оптимальным. В общем случае нельзя сказать, можно ли получить оптимальное решение с помощью жадного алгоритма применительно к конкретной задаче. Но есть две особенности, характерные для задач, которые решаются с помощью жадных алгоритмов: принцип жадного выбора и свойство оптимальности для подзадач. Принцип жадного выбора
Говорят, что к задаче оптимизации применим принцип жадного выбора, если последовательность локально оптимальных выборов дает глобально оптимальное решение. В этом состоит главное отличие жадных алгоритмов от динамического программирования: во втором просчитываются сразу последствия всех вариантов.
Чтобы доказать, что жадный алгоритм дает оптимум, нужно попытаться провести доказательство, аналогичное доказательству алгоритма задачи о выборе заявок. Сначала мы показываем, что жадный выбор на первом шаге не закрывает путь к оптимальному решению: для любого решения есть другое, согласованное с жадным выбором и не хуже первого. Потом мы показываем, что подзадача, возникшая после жадного выбора на первом шаге, аналогична исходной. По индукции будет следовать, что такая последовательность жадных выборов дает оптимальное решение.
-
Задача NP-полная (NP-complete problem)
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Тип задач, принадлежащих классу NP (non-deterministic polynomial – «недетерминированные с полиномиальным временем»), для которых отсутствуют быстрые алгоритмы решения. Время работы алгоритмов решения таких задач существенно (обычно, экспоненциально) возрастает с увеличением объема входных данных.
Однако, если предоставить алгоритму некоторые дополнительные сведения, то временные затраты могут быть существенно снижены. При этом, если будет найден быстрый алгоритм для какой-либо из NP-полных задач, то для любой другой задачи из класса NP можно будет найти соответствующее решение.
В теории алгоритмов - задача с ответом «да» или «нет» из класса NP, к которой можно свести любую другую задачу из этого класса за полиномиальное время (то есть при помощи операций, число которых не превышает некоторого полинома в зависимости от размера исходных данных).
Таким образом, NP-полные задачи образуют в некотором смысле подмножество «типовых» задач в классе NP: если для какой-то из них найден «полиномиально быстрый» алгоритм решения, то и любая другая задача из класса NP может быть решена так же «быстро».
К классу NP-полных относятся задача о коммивояжере, о вершинном покрытии и покрытии множеств.
-
Хэш-таблица (Hash Table)
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Структура данных, основанная на хэш-функции, которая преобразует ключ в индекс массива для хранения значения.
Преимущества:
- Быстрый доступ, вставка и удаление элементов (в среднем O(1))
- Гибкость структуры
Недостатки:
- Возможность коллизий хэш-функции
- Затраты памяти на хранение элементов и обработку коллизий
Применение:
- Хэш-таблицы используются в поисковых алгоритмах, кэшировании данных, реализации ассоциативных массивов и словарей.
-
Стэк(Stack)
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Cтруктура данных, организованная по принципу "последний пришел, первый ушел" (LIFO). Элементы добавляются и удаляются с одного конца структуры.
Преимущества:
- Простота реализации
- Легкость использования в рекурсии и отката операций
Недостатки:
- Ограниченный доступ к элементам (только к вершине стека)
Применение:
- Стеки полезны при выполнении рекурсивных функций, обработке скобочных последовательностей и отмене операций.
-
Очередь (Queue)
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Структура данных, организованная по принципу "первый пришел, первый ушел" (FIFO). Элементы добавляются в конец очереди и удаляются из начала.
Преимущества:
- Поддержка естественного порядка обработки элементов
- Применение в алгоритмах обхода и поиска
Недостатки:
- Ограниченный доступ к элементам (только к началу и концу очереди)
Применение:
- Очереди используются в алгоритмах обхода в ширину, приоритетных очередях и многопоточных приложениях для обработки задач.
Виды:
- Простая очередь
- Круговая очередь
- Очередь с приоритетом
- Двухсторонняя очередь https://codechick.io/tutorials/dsa/dsa-queue
-
Связанный список (Linked List)
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Связанный список - это структура данных, состоящая из узлов, каждый из которых содержит значение элемента и указатель на следующий узел в списке.
Существуют односвязные списки, где каждый узел имеет указатель только на следующий узел, двусвязные списки, где узлы имеют указатели на предыдущий и следующий узлы и кольцевые.
Преимущества:
- Динамическое изменение размера списка (в отличие от массивов)
- Эффективное добавление и удаление элементов в начале или конце списка
- Относительно простая реализация
Недостатки:
- Непостоянное время доступа к элементам (в отличие от массивов)
- Больший объем занимаемой памяти по сравнению с массивами из-за хранения указателей на узлы
Применение:
- Связанные списки подходят для реализации стеков, очередей, а также для задач, где требуется частое добавление или удаление элементов и не требуется быстрый доступ к элементам по индексу.
-
Граф (Graph)
- Джун: Начальные/Поверхностные знания.
- Мидл: Средние знания. Можете объяснить суть и есть опыт применения..
- Сеньор: Продвинутые знания. Можете показать на примере, знаете нюансы и можете научить.
Структура данных, состоящая из вершин (узлов) и ребер, которые соединяют эти вершины. Графы могут быть ориентированными (направленными) или неориентированными.
Преимущества:
- Отражение сложных отношений между элементами
- Гибкость структуры
Недостатки:
- Сложность реализации и обработки
- Большие затраты памяти
Применение:
- в транспортных сетях
- социальных сетях
- веб-технологиях
- задачи оптимизации
-
Куча (Heap)
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Куча (структура данных) — это полное двоичное дерево, удовлетворяющее свойству кучи: если узел A — это родитель узла B, то ключ узла A ≥ ключ узла B.
- Если любой узел всегда больше дочернего узла (узлов), а ключ корневого узла является наибольшим среди всех остальных узлов, это max-куча.
- Если любой узел всегда меньше дочернего узла (узлов), а ключ корневого узла является наименьшим среди всех остальных узлов, это min-куча.
-
Битовые поля (Bit Arrays)
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Битовые поля (Bit Arrays), где каждый бит представляет элемент данных. Часто используются для оптимизации использования памяти, когда нужно хранить множество флагов или булевых значений.
-
Массивы (Arrays)
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Массивы – это простейшая структура данных, представляющая собой набор элементов одного типа, расположенных последовательно в памяти. Хранит набор значений (элементов массива), идентифицируемых по индексу или набору индексов, принимающих целые (или приводимые к целым) значения из некоторого заданного непрерывного диапазона.
Преимущества:
Быстрый доступ к элементам по индексу Непрерывная область памятиНедостатки:
Фиксированный размер Неэффективное добавление/удаление элементовПрименение: Массивы подходят для хранения набора данных с фиксированным размером, где операции вставки и удаления элементов не требуются.
-
Двоичное дерево
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Двоичное дерево — древовидная структура данных, в которой у родительских узлов не может быть больше двух детей.
Типы двоичных деревьев
- Полное двоичное дерево — особый тип бинарных деревьев, в котором у каждого узла либо 0 потомков, либо 2.
- Совершенное двоичное дерево — особый тип бинарного дерева, в котором у каждого внутреннего узла по два ребенка, а листовые вершины находятся на одном уровне.
- Законченное двоичное дерево похоже на совершенное, но есть три большие отличия.
- Все уровни должны быть заполнены.
- Все листовые вершины склоняются влево.
- У последней листовой вершины может не быть правого собрата. Это значит, что завершенное дерево необязательно полное.
- Вырожденное двоичное дерево — дерево, в котором на каждый уровень приходится по одной вершине.
- Скошенное вырожденное дерево — вырожденное дерево, в котором есть либо только левые, либо только правые узлы. Таким образом, есть два типа скошенных деревьев — скошенные влево вырожденные деревья и скошенные вправо вырожденные деревья.
- Сбалансированное двоичное дерево — тип бинарного дерева, в котором у каждой вершины количество вершин в левом и правом поддереве различаются либо на 0, либо на 1.
-
Дерево двоичного поиска
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Дерево двоичного поиска — это структура данных, которая позволяет быстро работать с отсортированном списком чисел.
Дерево двоичное, потому что у каждого узла не более двух дочерних элементов.
Дерево поиска, потому что его можно использовать для проверки вхождения числа — за время O(log(n)).
Чем отличается от обычного двоичного дерева
Все узлы левого поддерева меньше корневого узла. Все узлы правого поддерева больше корневого узла. Оба поддерева каждого узла тоже являются деревьями двоичного поиска, т. е. также обладают первыми двумя свойствами.У правого дерева есть поддерево со значением 2, которое меньше, чем корень 3 — таким дерево двоичного поиска быть не может.
-
B-дерево
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
B-дерево (читается как Би-дерево) — это особый тип сбалансированного дерева поиска, в котором каждый узел может содержать более одного ключа и иметь более двух дочерних элементов. Из-за этого свойства B-дерево называют сильноветвящимся.
Зачем нужно
Вторичные запоминающие устройства (жесткие диски, SSD) медленно работают с большим объемом данных. Людям захотелось сократить время доступа к физическим носителям информации, поэтому возникла потребность в таких структурах данных, которые способны это сделать.
Двоичное дерево поиска, АВЛ-дерево, красно-черное дерево и т. д. могут хранить только один ключ в одном узле. Если нужно хранить больше, высота деревьев резко начинает расти, из-за этого время доступа сильно увеличивается.
С B-деревом все не так. Оно позволяет хранить много ключей в одном узле и при этом может ссылаться на несколько дочерних узлов. Это значительно уменьшает высоту дерева и, соответственно, обеспечивает более быстрый доступ к диску.
Свойства
- Ключи в каждом узле x упорядочены по неубыванию.
- В каждом узле есть логическое значение x.leaf. Оно истинно, если x — лист.
- Каждый узел, кроме корня, содержит не менее t-1 ключей, а каждый внутренний узел имеет как минимум t дочерних узлов, где t — минимальная степень B-дерева.
- Все листья находятся на одном уровне, т. е. обладают одинаковой глубиной, равной высоте дерева.
- Корень имеет не менее 2 дочерних элементов и содержит не менее 1 ключа.
-
R-дерево
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
R-дерево (R-trees) — древовидная структура данных (дерево). Она подобна B-дереву, но используется для организации доступа к пространственным данным, то есть для индексации многомерной информации, такой, например, как географические данные с двумерными координатами (широтой и долготой). Типичным запросом с использованием R-деревьев мог бы быть такой: «Найти все музеи в пределах 2 километров от моего текущего местоположения».
Эта структура данных разбивает многомерное пространство на множество иерархически вложенных и, возможно, пересекающихся, прямоугольников (для двумерного пространства). В случае трехмерного или многомерного пространства это будут прямоугольные параллелепипеды (кубоиды) или параллелотопы.
Алгоритмы вставки и удаления используют эти ограничивающие прямоугольники для обеспечения того, чтобы «близкорасположенные» объекты были помещены в одну листовую вершину. В частности, новый объект попадёт в ту листовую вершину, для которой потребуется наименьшее расширение её ограничивающего прямоугольника. Каждый элемент листовой вершины хранит два поля данных: способ идентификации данных, описывающих объект, (либо сами эти данные) и ограничивающий прямоугольник этого объекта.
Аналогично, алгоритмы поиска (например, пересечение, включение, окрестности) используют ограничивающие прямоугольники для принятия решения о необходимости поиска в дочерней вершине. Таким образом, большинство вершин никогда не затрагиваются в ходе поиска. Как и в случае с B-деревьями, это свойство R-деревьев обусловливает их применимость для баз данных, где вершины могут выгружаться на диск по мере необходимости.
Для расщепления переполненных вершин могут применяться различные алгоритмы, что порождает деление R-деревьев на подтипы: квадратичные и линейные.
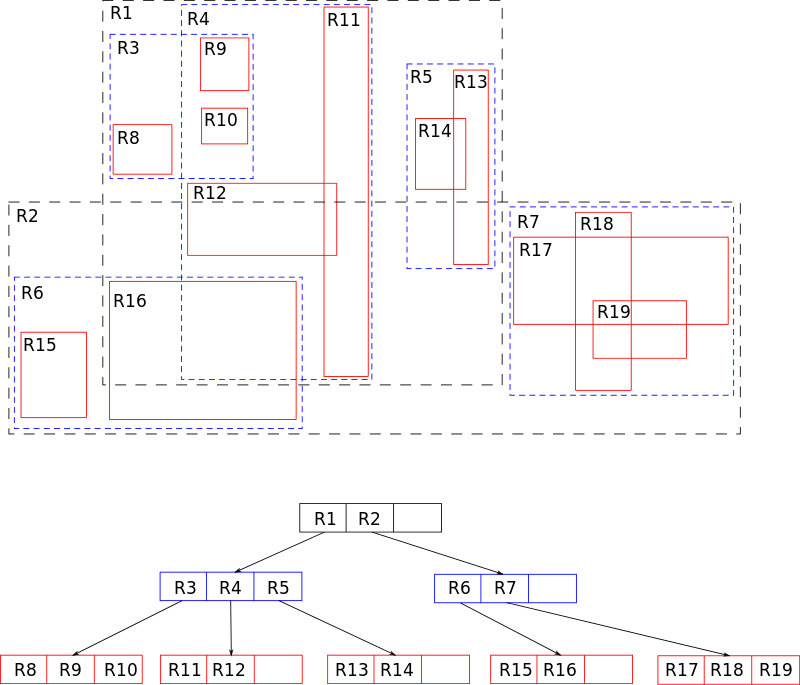
Структура R-дерева
Каждая вершина R-дерева имеет переменное количество элементов (не более некоторого заранее заданного максимума). Каждый элемент нелистовой вершины хранит два поля данных: способ идентификации дочерней вершины и ограничивающий прямоугольник (кубоид), охватывающий все элементы этой дочерней вершины. Все хранимые кортежи хранятся на одном уровне глубины, таким образом, дерево идеально сбалансировано. При проектировании R-дерева нужно задать некоторые константы:
MaxEntries — максимальное число детей у вершины MinEntries — минимальное число детей у вершины, за исключением корня.Для корректной работы алгоритмов необходимо выполнение условия MinEntries <= MaxEntries / 2. В корневой вершине может быть от 2 до MaxEntries потомков. Часто выбирают MinEntries = 2, тогда для корня выполняются те же условия, что и для остальных вершин. Также иногда разумно выделять отдельные константы для количества точек в листовых вершинах, так как их часто можно делать больше.
-
АВЛ-дерево
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
сбалансированное по высоте двоичное дерево поиска: для каждой его вершины высота её двух поддеревьев различается не более чем на 1.
-
LSM Дерево
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
LSM-дерево (Log-structured merge-tree — журнально-структурированное дерево со слиянием) — используемая во многих СУБД структура данных, предоставляющая быстрый доступ по индексу в условиях частых запросов на вставку (например, при хранении журналов транзакций). LSM-деревья, как и другие деревья, хранят пары «ключ — значение». LSM-дерево поддерживает две или более различные структуры, каждая из которых оптимизирована под устройство, в котором она будет храниться. Синхронизация между этими структурами происходит блоками. Принцип работы
Простая версия LSM-дерева — двухуровневое дерево — состоит из двух древоподобных структур C0 и C1. C0 меньше по размеру и хранится целиком в оперативной памяти, а C1 находится в энергонезависимой памяти. Новые записи вставляются в C0. Если после вставки размер C0 превышает некоторое заданное пороговое значение, непрерывный сегмент удаляется из C0 и сливается с C1 на устройстве постоянного хранения. Хорошая производительность достигается за счёт того, что деревья оптимизированы под своё хранилище, а слияние осуществляется эффективно и группами по нескольку записей, используя алгоритм, напоминающий сортировку слиянием.
Большинство LSM-деревьев, используемых на практике, реализует несколько уровней. Уровень 0 (назовём его MemTable) хранится в оперативной памяти и может быть представлен обычным деревом. Данные на устройствах постоянного хранения хранятся в виде отсортированных по ключу таблиц (SSTable). Таблица может храниться в виде отдельного файла или набора файлов с непересекающимися значениями ключей. Для поиска конкретного ключа нужно проверить его наличие в MemTable, а затем — пройти по всем SSTable на устройстве постоянного хранения. Схема работы с LSM-деревом:
индексы SSTable всегда загружены в оперативную память; запись производится в MemTable; при чтении сначала проверяется MemTable, а затем, если надо, — SSTable на устройстве постоянного хранения; периодически MemTable сбрасывается в энергонезависимую память для постоянного хранения в виде SSTable; периодически SSTable на устройствах постоянного хранения сливаются.Искомый ключ может появиться сразу в нескольких таблицах на устройствах постоянного хранения, и итоговый ответ зависит от программы. Большинству приложений нужно лишь последнее значение, относящееся к данному ключу. Другие, например Apache Cassandra, в которой каждое значение представляет собой строку базы данных (а строка может иметь разное количество столбцов в разных таблицах с устройств постоянного хранения), вынуждены как-либо обрабатывать все имеющиеся значения, чтобы получить корректный результат. Чтобы сократить время выполнения запросов, на практике стараются избегать ситуации со слишком большим количеством таблиц на устройствах постоянного хранения.
Были разработаны расширения к «уровневому» методу для поддержания B+-структур, например, bLSM[2] и Diff-Index.[3] Время работы
Архитектура LSM-дерева позволяет удовлетворить запрос на чтение либо из оперативной памяти, либо за одно обращение к устройствам постоянного хранения. Запись тоже всегда быстра независимо от размеров хранилища.
SSTable на устройствах постоянного хранения неизменяема. Поэтому изменения хранятся в MemTable, а удаления должны добавлять в MemTable специальное значение. Поскольку новые считывания происходят последовательно по индексу, обновлённое значение или запись об удалении значения встретятся раньше, чем старые значения. Периодически запускаемое слияние старых SSTable на устройстве постоянного хранения будет производить эти изменения и действительно удалять и обновлять значения, избавляясь от ненужных данных.
-
Сортировка пузырьком / Bubble sort
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Или сортировка простыми обменами. Обходим массив от начала до конца, попутно меняя местами неотсортированные соседние элементы. В результате первого прохода на последнее место «всплывёт» максимальный элемент. Теперь снова обходим неотсортированную часть массива (от первого элемента до предпоследнего) и меняем по пути неотсортированных соседей. Второй по величине элемент окажется на предпоследнем месте. Если за проход не произошло ни одного обмена, то массив отсортирован. Продолжая в том же духе, будем обходить всё уменьшающуюся неотсортированную часть массива, запихивая найденные максимумы в конец. Очевидно, не более чем после n итераций массив будет отсортирован.
-
Сортировка вставками / Insertion sort
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Элементы входной последовательности просматриваются по одному, и каждый новый поступивший элемент размещается в подходящее место среди ранее упорядоченных элементов.
-
Сортировка выбором / Selection sort
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
На очередной итерации будем находить минимум в массиве после текущего элемента и менять его с ним, если надо. Таким образом, после i-ой итерации первые i элементов будут стоять на своих местах. Нужно отметить, что эту сортировку можно реализовать двумя способами – сохраняя минимум и его индекс или просто переставляя текущий элемент с рассматриваемым, если они стоят в неправильном порядке.
-
Быстрая сортировка / Quicksort
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Выбрать из массива элемент, называемый опорным(pivot). Это может быть любой из элементов массива. От выбора опорного элемента не зависит корректность алгоритма, но в отдельных случаях может сильно зависеть его эффективность. В ранних реализациях, как правило, опорным выбирался первый элемент, что снижало производительность на отсортированных массивах. Для улучшения эффективности может выбираться средний, случайный элемент или (для больших массивов) медиана первого, среднего и последнего элементов. Медиана всей последовательности является оптимальным опорным элементом, но её вычисление слишком трудоёмко для использования в сортировке. Сравнить все остальные элементы с опорным и переставить их в массиве так, чтобы разбить массив на три непрерывных отрезка, следующих друг за другом: «элементы меньшие опорного», «равные» и «большие». На практике массив обычно делят не на три, а на две части: например, «меньшие опорного» и «равные и большие»; такой подход в общем случае эффективнее, так как упрощает алгоритм разделения Для отрезков «меньших» и «больших» значений выполнить рекурсивно ту же последовательность операций, если длина отрезка больше единицы.
-
Сортировка слиянием / Merge sort
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Сортировка, основанная на парадигме «разделяй и властвуй». Разделим массив пополам, рекурсивно отсортируем части, после чего выполним процедуру слияния: поддерживаем два указателя, один на текущий элемент первой части, второй – на текущий элемент второй части. Из этих двух элементов выбираем минимальный, вставляем в ответ и сдвигаем указатель, соответствующий минимуму. Слияние работает за O(n), уровней всего logn, поэтому асимптотика O(n logn). Эффективно заранее создать временный массив и передать его в качестве аргумента функции. Эта сортировка рекурсивна, как и быстрая, а потому возможен переход на квадратичную при небольшом числе элементов.
-
Сортировка кучей
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
ßКуча (heap) — это не что иное, как двоичное дерево с некоторыми дополнительными правилами, которым оно должно следовать: во-первых, оно всегда должно иметь структуру кучи, где все уровни двоичного дерева заполняются слева направо, и, во-вторых, оно должно быть упорядочено в виде max-кучи или min-кучи. В качестве примера я буду использовать min-кучу.
Алгоритм пирамидальной сортировки — это метод сортировки, который полагается на такие структуры данных как двоичные кучи. Поскольку мы знаем, что кучи всегда должны соответствовать определенным требованиям, мы можем использовать это для поиска элемента с наименьшим значением, последовательно сортируя элементы, выбирая корневой узел кучи и добавляя его в конец массива.
Работает в худшем, в среднем и в лучшем случае (то есть гарантированно) за O(n*log n) операций при сортировке n элементов. Количество применяемой служебной памяти не зависит от размера массива O(1). Может рассматриваться как усовершенствованная сортировка пузырьком, в которой элемент всплывает/тонет по многим путям.
https://backendinterview.ru/algostruct/graph.html https://backendinterview.ru/algostruct/index.html
https://habr.com/ru/companies/otus/articles/770248/ https://habr.com/ru/companies/otus/articles/782064/ https://habr.com/ru/companies/ruvds/articles/732648/
Криптогра́фия — наука о методах обеспечения конфиденциальности (невозможности прочтения информации посторонним), целостности данных (невозможности незаметного изменения информации), аутентификации (проверки подлинности авторства или иных свойств объекта), а также невозможности отказа от авторства.
https://habr.com/ru/articles/549054/ https://habr.com/ru/articles/587620/ https://xbsoftware.ru/blog/metodologii-testirovaniya-po-kakuyu-vybrat/
Технологии используемые в разработке для развертывания и деплоя
https://habr.com/ru/articles/258443/ https://kubernetes.io/ru/docs/concepts/overview/what-is-kubernetes/
- Сервисы метрик и логирования
Базы данны SQL, NoSQL и сервисы очередей
Транзакционные базы данных (базы, работающие через транзакции) выполняют требования ACID, которые обеспечивают безопасность данных.
https://habr.com/ru/articles/537594/ https://ru.wikipedia.org/wiki/Транзакция_(информатика)
https://habr.com/ru/companies/tensor/articles/779698/ https://habr.com/ru/articles/340460/
Знания языка программирования PHP
PHP vendors
Навыки связанные с client-side разработкой
-
Минификация
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Cжатие js/css кода для ускорения загрузки
https://sky.pro/wiki/javascript/minimizaciya-i-obuedinenie-css-i-js/
-
Транспиляция
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Преобразование кода на новую версию или другой язык
-
Code Splitting
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Разделение кода на пакеты, чтоб загружать его по мере необходимости.
Применяется совместно с Lazy Loading
-
Форматы изображений
- Знакомо: Имею общее представление о большинстве форматах
- Знаю: Знаю плюсы и минусы основных форматов jpg, png, gif, svg, ico
- Понимаю: Понимаю и могу объяснить как устроены алгоритмы сжатия в различных форматах.
Растровые и векторные форматы изображений (jpg, png, gif, svg, ico, tiff, avif, apng, hiec, webp, bmp, raw и т.д.).
Оптимизация и особенности применения.
-
SVG
- Знаю: Базовый синтаксис и принцип работы
- Понимаю и применяю: Могу поменять текст, сформировать новое изображение с нуля, анимировать графику
-
Оптимизация загрузки ресурсов
- Джун: Начальные/Поверхностные знания.
- Мидл: Средние знания. Можете объяснить суть и есть опыт применения..
- Сеньор: Продвинутые знания. Можете показать на примере, знаете нюансы и можете научить.
способы подключения ресурсов (async/defer, prefetch/preload)
Preload, prefetch и другие теги https://habr.com/ru/articles/445264/
Разница между async и defer у тега script https://wp-kama.ru/id_12151/raznitsa-async-defer.html
Как быстрее DOM построить: парсинг, async, defer и preload https://habr.com/ru/articles/338840/
-
CDN
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Хранение статики
-
Service Worker
- Джун: Начальные/Поверхностные знания.
- Мидл: Средние знания. Можете объяснить суть и есть опыт применения..
- Сеньор: Продвинутые знания. Можете показать на примере, знаете нюансы и можете научить.
Основное назначение - Push уведомления, фоновая синхронизация и кэшерование.
https://developer.mozilla.org/ru/docs/Web/API/Service_Worker_API/Using_Service_Workers
https://learn.javascript.ru/first-steps https://habr.com/ru/companies/ruvds/articles/416375/
-
.call и .apply
- Знаю: Знаю что это, читал/изучал.
разница между .call и .apply
-
cookie, sessionStorage и localStorage
- Джун: Начальные/Поверхностные знания.
- Мидл: Средние знания. Можете объяснить суть и есть опыт применения..
- Сеньор: Продвинутые знания. Можете показать на примере, знаете нюансы и можете научить.
Разница и ограничения cookie, sessionStorage и localStorage.
https://learn.javascript.ru/localstorage?ysclid=m4f9fptrr1171420958
-
let, var и const
- Знаю: Знаю что это, читал/изучал.
Разница между let, var и const
-
Обработка ошибок и исключений
- Знаю: Знаю что это, читал/изучал.
Обработка ошибок и исключений
-
Fetch
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
https://developer.mozilla.org/en-US/docs/Web/API/Fetch_API/Using_Fetch
-
CORS
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
CORS (Cross-Origin Resource Sharing, англ. «совместное использование ресурсов разных источников») — это стандарт, позволяющий предоставлять веб-страницам доступ к объектам сторонних интернет-ресурсов. Сторонним считается любой интернет-ресурс, который отличается от запрашиваемого протоколом, доменом или портом.
Доступ предоставляется по специализированным запросам. Интернет-ресурс, принимающий запрос, содержит список доверенных источников, которым разрешен доступ к объектам. Страница-источник запроса получает доступ, если входит в список доверенных источников. Для предоставления доступа всем сторонним интернет-страницам используется маска «*». Как появился стандарт
Первоначально для защиты информации была разработана «Политика одинакового источника» (Same-Origin Policy, SOP). Поддерживающий политику SOP веб-браузер сверяет комбинации сетевого протокола (например, https), точное имя домена и номер порта, чтобы разрешить доступ к ресурсам веб-страницы по запросам с другой страницы. Политика SOP не обязательна к применению, однако все современные веб-браузеры ее поддерживают.
Если веб-ресурсы интернет-источника соответствуют SOP, для доступа к ним из другого источника браузер должен поддерживать технологию Cross-Origin Resource Sharing. В 2006 году рабочая группа Консорциума Всемирной паутины (World Wide Web Consortium, W3C – организация, разрабатывающая интернет-стандарты) представила первый рабочий проект этой технологии. В 2014 году CORS был принят в качестве Рекомендации W3C. Структура Cross-Origin Resource Sharing
Методы CORS предназначены для управления доступом к дескрипторам (тегам) на веб-страницах в сети. Управляемые типы доступа подразделяются на три основных категории по работе с информацией сторонних ресурсов:
Доступ на запись — это доступ к ссылкам, заполнению веб-форм и переадресации на сторонние веб-страницы, т.е. на передачу информации в сторонний источник (веб-ресурс).
Доступ на вставку относится к категории доступа на считывание информации из стороннего источника. К этому типу принадлежат вставки в код дескрипторов audio, video, img, embed, object, link, script, iframe и другие элементы оформления веб-страниц. Структура подобных дескрипторов подразумевает самостоятельную инициацию перекрестных (cross-origin) запросов из сторонних источников. Все дескрипторы этой категории представляют низкий уровень угрозы безопасности, поэтому разрешены в веб-браузере по умолчанию.
Доступ на считывание — это дескрипторы, загружаемые с использованием фоновых методов вызова, таких как fetch(), технологии обмена данными Ajax и пр. Поскольку подобные дескрипторы могут содержать в теле любые участки кода (в том числе вредоносного), они запрещены в веб-браузерах по умолчанию.
При настройке веб-сайта механизм CORS позволяет выборочно блокировать различные категории доступа пользователя к ресурсам (запись, вставку или считывание).
https://yandex.cloud/ru/docs/glossary/cors https://habr.com/ru/companies/macloud/articles/553826/
-
Event loop
- Знаю: Знаю что это, читал/изучал.
Event loop
-
Сypress
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Фреймворк для автоматизированного тестирования
https://docs.cypress.io/app/get-started/why-cypress https://habr.com/ru/companies/otus/articles/672098/
https://habr.com/ru/companies/piter/articles/820027/ https://habr.com/ru/companies/macloud/articles/559902/
https://itanddigital.ru/bloghrconsulting/tpost/o9gce6b1b1-50-osnovnih-voprosov-i-otvetov-na-sobese
Webpack — это модульный сборщик (bundler) с открытым исходным кодом, написанный на JavaScript.
Он берёт несколько скриптов JavaScript с их зависимостями и объединяет в файл, который используется браузером.
Преимущества Webpack:
ускоряет разработку, убирая необходимость постоянно перезагружать веб-страницу при изменениях в JS-файлах;
обеспечивает разделение кода на отдельные модули, которые можно переиспользовать внутри веб-приложения;
позволяет избежать проблем с перезаписью глобальных переменных;
поддерживает минификацию, то есть сокращение объёма кода без изменения его функциональности;
умеет работать с разными спецификациями модулей.-
Псевдо-классы
- Знаю: Знаю что это, читал/изучал.
псевдо-классы
-
Нормализаця стилей
- Знаю: Знаю что это, читал/изучал.
нормализаця стилей
-
Медиазапросы
- Знаю: Знаю что это, читал/изучал.
Медиазапросы
-
animation,transition,transform
- Знаю: Знаю что это, читал/изучал.
animation,transition,transform
CSS фреймворки
Навыки по разработке приложений для Android
Навыки по разработке приложений на iOS, для iPhone , iMac
https://help.ubuntu.com/kubuntu/desktopguide/ru/linux-basics.html https://habr.com/ru/articles/655275/
Сетевые протоколы (IP, Transport, etc)
Soft skills
https://blog.karpachoff.com/kommunikativnye-navyki-kak-ih-razvit-i-uluchshit
Устная, письменна, и чтение.
Методы достижения целей
Бизнес-анализ