Матрица пользователя : Ara-Arakel28
- Заполненных тем 24
- Заполненных навыков 129
- PHP Data social Paradigms Frontend Search Сеть sql OOP Javascript
- 2737
- 2025-01-06 19:07:35
- Предыдущий триал 2827
Hard skills
Пет проекты и сервисы
-
YAGNI
- Знаю: Знаю что это, читал/изучал.
AGNI («You aren't gonna need it»; с англ. — «Вам это не понадобится») — процесс и принцип проектирования ПО, при котором в качестве основной цели и/или ценности декларируется отказ от избыточной функциональности, — то есть отказ добавления функциональности, в которой нет непосредственной надобности.
Согласно адептам принципа YAGNI, желание писать код, который не нужен прямо сейчас, но может понадобиться в будущем, приводит к следующим нежелательным последствиям:
Тратится время, которое было бы затрачено на добавление, тестирование и улучшение необходимой функциональности. Новые функции должны быть отлажены, документированы и сопровождаться. Новая функциональность ограничивает то, что может быть сделано в будущем, — ненужные новые функции могут впоследствии помешать добавить новые нужные. Пока новые функции действительно не нужны, трудно полностью предугадать, что они должны делать, и протестировать их. Если новые функции тщательно не протестированы, они могут неправильно работать, когда впоследствии понадобятся. Это приводит к тому, что программное обеспечение становится более сложным (подчас чрезмерно сложным). Если вся функциональность не документирована, она может так и остаться неизвестной пользователям, но может создать различные риски для безопасности пользовательской системы. Добавление новой функциональности может привести к желанию ещё более новой функциональности, приводя к эффекту «снежного кома». -
TDD
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Разработка через тестирование (англ. test-driven development, TDD) — техника разработки программного обеспечения, которая основывается на повторении очень коротких циклов разработки: сначала пишется тест, покрывающий желаемое изменение, затем пишется код, который позволит пройти тест, и под конец проводится рефакторинг нового кода к соответствующим стандартам. Кент Бек, считающийся изобретателем этой техники, утверждал в 2003 году, что разработка через тестирование поощряет простой дизайн и внушает уверенность (англ. inspires confidence).
Преимущества
Исследование 2005 года показало, что использование разработки через тестирование предполагает написание большего количества тестов, в свою очередь, программисты, пишущие больше тестов, склонны быть более продуктивными.[5] Гипотезы, связывающие качество кода с TDD, были неубедительны.[6]
Программисты, использующие TDD на новых проектах, отмечают, что они реже ощущают необходимость использовать отладчик. Если некоторые из тестов неожиданно перестают проходить, откат к последней версии, которая проходит все тесты, может быть более продуктивным, нежели отладка.[7]
Разработка через тестирование предлагает больше, чем просто проверку корректности, она также влияет на дизайн программы. Изначально сфокусировавшись на тестах, проще представить, какая функциональность необходима пользователю. Таким образом, разработчик продумывает детали интерфейса до реализации. Тесты заставляют делать свой код более приспособленным для тестирования. Например, отказываться от глобальных переменных, одиночек (singletons), делать классы менее связанными и легкими для использования. Сильно связанный код или код, который требует сложной инициализации, будет значительно труднее протестировать. Модульное тестирование способствует формированию четких и небольших интерфейсов. Каждый класс будет выполнять определенную роль, как правило, небольшую. Как следствие, зацепление между классами будут снижаться, а связность повышаться. Контрактное программирование (англ. design by contract) дополняет тестирование, формируя необходимые требования через утверждения (англ. assertions).
Несмотря на то, что при разработке через тестирование требуется написать большее количество кода, общее время, затраченное на разработку, обычно оказывается меньше. Тесты защищают от ошибок. Поэтому время, затрачиваемое на отладку, снижается многократно.[8] Большое количество тестов помогает уменьшить количество ошибок в коде. Устранение дефектов на более раннем этапе разработки, препятствует появлению хронических и дорогостоящих ошибок, приводящих к длительной и утомительной отладке в дальнейшем.
Тесты позволяют производить рефакторинг кода без риска его испортить. При внесении изменений в хорошо протестированный код риск появления новых ошибок значительно ниже. Если новая функциональность приводит к ошибкам, тесты, если они, конечно, есть, сразу же это покажут. При работе с кодом, на который нет тестов, ошибку можно обнаружить спустя значительное время, когда с кодом работать будет намного сложнее. Хорошо протестированный код легко переносит рефакторинг. Уверенность в том, что изменения не нарушат существующую функциональность, придает уверенность разработчикам и увеличивает эффективность их работы. Если существующий код хорошо покрыт тестами, разработчики будут чувствовать себя намного свободнее при внесении архитектурных решений, которые призваны улучшить дизайн кода.
Разработка через тестирование способствует более модульному, гибкому и расширяемому коду. Это связано с тем, что при этой методологии разработчику необходимо думать о программе как о множестве небольших модулей, которые написаны и протестированы независимо и лишь потом соединены вместе. Это приводит к меньшим, более специализированным классам, уменьшению связанности и более чистым интерфейсам. Использование mock-объектов также вносит вклад в модуляризацию кода, поскольку требует наличия простого механизма для переключения между mock- и обычными классами.
Поскольку пишется лишь тот код, что необходим для прохождения теста, автоматизированные тесты покрывают все пути исполнения. Например, перед добавлением нового условного оператора разработчик должен написать тест, мотивирующий добавление этого условного оператора. В результате получившиеся в результате разработки через тестирование тесты достаточно полны: они обнаруживают любые непреднамеренные изменения поведения кода.
Тесты могут использоваться в качестве документации. Хороший код расскажет о том, как он работает, лучше любой документации. Документация и комментарии в коде могут устаревать. Это может сбивать с толку разработчиков, изучающих код. А так как документация, в отличие от тестов, не может сказать, что она устарела, такие ситуации, когда документация не соответствует действительности — не редкость.
Слабые места
Существуют задачи, которые невозможно (по крайней мере, на текущий момент) решить только при помощи тестов. В частности, TDD не позволяет механически продемонстрировать адекватность разработанного кода в области безопасности данных и взаимодействия между процессами. Безусловно, безопасность основана на коде, в котором не должно быть дефектов, однако она основана также на участии человека в процедурах защиты данных. Тонкие проблемы, возникающие в области взаимодействия между процессами, невозможно с уверенностью воспроизвести, просто запустив некоторый код. Разработку через тестирование сложно применять в тех случаях, когда для тестирования необходимо прохождение функциональных тестов. Примерами может быть: разработка интерфейсов пользователя, программ, работающих с базами данных, а также того, что зависит от специфической конфигурации сети. Разработка через тестирование не предполагает большого объёма работы по тестированию такого рода вещей. Она сосредотачивается на тестировании отдельно взятых модулей, используя mock-объекты для представления внешнего мира. Требуется больше времени на разработку и поддержку, а одобрение со стороны руководства очень важно. Если у организации нет уверенности в том, что разработка через тестирование улучшит качество продукта, то время, потраченное на написание тестов, может рассматриваться как потраченное впустую.[9] Модульные тесты, создаваемые при разработке через тестирование, обычно пишутся теми же, кто пишет тестируемый код. Если разработчик неправильно истолковал требования к приложению, и тест, и тестируемый модуль будут содержать ошибку. Большое количество используемых тестов может создать ложное ощущение надежности, приводящее к меньшему количеству действий по контролю качества. Тесты сами по себе являются источником накладных расходов. Плохо написанные тесты, например, содержат жёстко вшитые строки с сообщениями об ошибках или подвержены ошибкам, дороги при поддержке. Чтобы упростить поддержку тестов, следует повторно использовать сообщения об ошибках из тестируемого кода. Уровень покрытия тестами, получаемый в результате разработки через тестирование, не может быть легко получен впоследствии. Исходные тесты становятся всё более ценными с течением времени. Если неудачные архитектура, дизайн или стратегия тестирования приводят к большому количеству непройденных тестов, важно их все исправить в индивидуальном порядке. Простое удаление, отключение или поспешное изменение их может привести к необнаруживаемым пробелам в покрытии тестами.Видимость кода
Набор тестов должен иметь доступ к тестируемому коду. С другой стороны, принципы инкапсуляции и сокрытия данных не должны нарушаться. Поэтому модульные тесты обычно пишутся в том же модуле или проекте, что и тестируемый код.
Из кода теста может не быть доступа к приватным (англ. private) полям и методам. Поэтому при модульном тестировании может потребоваться дополнительная работа. В Java разработчик может использовать отражение (англ. reflection), чтобы обращаться к полям, помеченными как приватные.[10] Модульные тесты можно реализовать во внутренних классах, чтобы они имели доступ к членам внешнего класса. В .NET Framework могут применяться разделяемые классы (англ. partial classes) для доступа из теста к приватным полям и методам.
Важно, чтобы фрагменты кода, предназначенные исключительно для тестирования, не оставались в выпущенном коде. В Си для этого могут быть использованы директивы условной компиляции. Однако это будет означать, что выпускаемый код не полностью совпадает с протестированным. Систематический запуск интеграционных тестов на выпускаемой сборке поможет удостовериться, что не осталось кода, скрыто полагающегося на различные аспекты модульных тестов.
Не существует единого мнения среди программистов, применяющих разработку через тестирование, о том, насколько осмысленно тестировать приватные, защищённые(англ. protected) методы, а также данные. Одни убеждены, что достаточно протестировать любой класс только через его публичный интерфейс, поскольку приватные переменные — это всего лишь деталь реализации, которая может меняться, и её изменения не должны отражаться на наборе тестов. Другие утверждают, что важные аспекты функциональности могут быть реализованы в приватных методах и тестирование их неявно через публичный интерфейс лишь усложнит ситуацию: модульное тестирование предполагает тестирование наименьших возможных модулей функциональности.
Fake-, mock-объекты и интеграционные тесты
Модульные тесты тестируют каждый модуль по отдельности. Неважно, содержит ли модуль сотни тестов или только пять. Тесты, используемые при разработке через тестирование, не должны пересекать границы процесса, использовать сетевые соединения. В противном случае прохождение тестов будет занимать большое время, и разработчики будут реже запускать набор тестов целиком. Введение зависимости от внешних модулей или данных также превращает модульные тесты в интеграционные. При этом если один модуль в цепочке ведет себя неправильно, может быть не сразу понятно какой именно[источник не указан 4378 дней].
Когда разрабатываемый код использует базы данных, веб-сервисы или другие внешние процессы, имеет смысл выделить покрываемую тестированием часть. Это делается в два шага:
Везде, где требуется доступ к внешним ресурсам, должен быть объявлен интерфейс, через который этот доступ будет осуществляться. См. принцип инверсии зависимостей (англ. dependency inversion) для обсуждения преимуществ этого подхода независимо от TDD. Интерфейс должен иметь две реализации. Первая, собственно предоставляющая доступ к ресурсу, и вторая, являющаяся fake- или mock-объектом. Всё, что делают fake-объекты, это добавляют сообщения вида «Объект person сохранен» в лог, чтобы потом проверить правильность поведения. Mock-объекты отличаются от fake- тем, что сами содержат утверждения (англ. assertion), проверяющие поведение тестируемого кода. Методы fake- и mock-объектов, возвращающие данные, можно настроить так, чтобы они возвращали при тестировании одни и те же правдоподобные данные. Они могут эмулировать ошибки так, чтобы код обработки ошибок мог быть тщательно протестирован. Другими примерами fake-служб, полезными при разработке через тестирование, могут быть: служба кодирования, которая не кодирует данные, генератор случайных чисел, который всегда выдает единицу. Fake- или mock-реализации являются примерами внедрения зависимости (англ. dependency injection).Использование fake- и mock-объектов для представления внешнего мира приводит к тому, что настоящая база данных и другой внешний код не будут протестированы в результате процесса разработки через тестирование. Чтобы избежать ошибок, необходимы тесты реальных реализаций интерфейсов, описанных выше. Эти тесты могут быть отделены от остальных модульных тестов и реально являются интеграционными тестами. Их необходимо меньше, чем модульных, и они могут запускаться реже. Тем не менее, чаще всего они реализуются используя те же библиотеки для тестирования (англ. testing framework), что и модульные тесты.
Интеграционные тесты, которые изменяют данные в базе данных, должны откатывать состоянии базы данных к тому, которое было до запуска теста, даже если тест не прошёл. Для этого часто применяются следующие техники:
Метод TearDown, присутствующий в большинстве библиотек для тестирования. try...catch...finally структуры обработки исключений, там где они доступны. Транзакции баз данных. Создание снимка (англ. snapshot) базы данных перед запуском тестов и откат к нему после окончания тестирования. Сброс базы данных в чистое состояние перед тестом, а не после них. Это может быть удобно, если интересно посмотреть состояние базы данных, оставшееся после не прошедшего теста.Существуют библиотеки Moq, jMock, NMock, EasyMock, Typemock, jMockit, Unitils, Mockito, Mockachino, PowerMock или Rhino Mocks, а также sinon для JavaScript предназначенные упростить процесс создания mock-объектов.
-
DDD
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Предметно-ориентированное проектирование (реже проблемно-ориентированное, англ. domain-driven design, DDD) — набор принципов и схем, направленных на создание оптимальных систем объектов. Сводится к созданию программных абстракций, которые называются моделями предметных областей. В эти модели входит бизнес-логика, устанавливающая связь между реальными условиями области применения продукта и кодом.
Предметно-ориентированное проектирование не является какой-либо конкретной технологией или методологией. DDD — это набор правил, которые позволяют принимать правильные проектные решения. Данный подход позволяет значительно ускорить процесс проектирования программного обеспечения в незнакомой предметной области.
Основные определения
Область (англ. domain) — предметная область, для которой разрабатывается программное обеспечение. Модель (англ. model) — описывает отдельные аспекты области и может быть использована для решения проблемы. Язык описания — используется для единого стиля описания домена и модели.Подход DDD особо полезен в ситуациях, когда разработчик не является специалистом в области разрабатываемого продукта. К примеру: программист не может знать все области, в которых требуется создать ПО, но с помощью правильного представления структуры, посредством предметно-ориентированного подхода, может без труда спроектировать приложение, основываясь на ключевых моментах и знаниях рабочей области.
Данный термин был впервые введен Э. Эвансом в его книге с таким же названием «Domain-Driven Design»
Элементы DDD
При проектировании на основе предметно-ориентированного подхода используются следующие понятия: Ограниченный контекст
В большинстве систем для предприятий используются крупномасштабные зоны ответственности. В DDD этот высший уровень организации называется ограниченным контекстом. Например, система биллинга крупной телекоммуникационной компании может иметь следующие ключевые элементы:
клиентская база система безопасности и защиты резервное копирование взаимодействие с платежными системами ведение отчётности администрирование система уведомленийВсе перечисленные элементы должны быть включены в единую, работающую без перебоев систему. При проектировании система уведомлений и система безопасности выделяются как совершенно разные вещи. Системы, в которых при реализации не удаётся разделить и изолировать ограниченные контексты, часто приобретают архитектурный стиль, который имеет красноречивое название «Большой ком грязи» в 1999 г. Брайан Фут (Brian Foot) и Йозеф Йодер (Joseph Yoder).[2]
Сутью предметно-ориентированного проектирования является конкретное определение контекстов и ограничение моделирования в их рамках. Сущность
Проще всего сущности выражать в виде существительных: люди, места, товары и т. д. У сущностей есть и индивидуальность, и жизненный цикл. Во время проектирования думать о сущностях следует как о единицах поведения, нежели как о единицах данных. Чаще всего какие-то операции, которые вы пытаетесь добавить в модель, должна получить какая-то сущность, или при этом начинает создаваться или извлекаться новая сущность. В более слабо связанном коде можно найти массу служебных или управляющих классов, проверяющих сущности снаружи. Объект-значение
Объект-значение — это свойства, важные в той предметной области, которую вы моделируете. У них, в отличие от сущностей, нет обозначения; они просто описывают конкретные сущности, которые уже имеют обозначения. Полезность объектов-значений состоит в том, что они описывают свойства сущностей гораздо более изящным и объявляющим намерения способом. Стоит всегда помнить, что значение объекта никогда не изменяется на протяжении выполнения всего программного кода. После их создания, внесение поправок невозможно. Агрегат
Агрегат — специальная сущность, к которой напрямую обращаются потребители. Использование агрегатов позволяет избегать чрезмерного соединения объектов, составляющих модель, между собой. Это позволяет избежать путаницы и упростить структуру, потому что не позволяет создавать тесно связанные системы. Службы предметных областей
Иногда в предметной области есть операции или процессы, у которых нет обозначения или жизненного цикла. Службы области дают инструмент для моделирования этих концепций. Они характеризуются отсутствием состояния и высокой связностью, часто предоставляя один открытый метод и иногда перегрузку для действий над наборами. Если в поведение включено несколько зависимостей, и нет возможности найти подходящего места в сущности для размещения этого поведения, в этом случае используют службу. Хотя сам по себе термин «служба» в мире разработки перегружен различными значениями, но в данной тематике, это обозначает небольшой класс, не представляющий конкретного человека, место или вещь в проектируемом приложении, но включающий в себя какие-то процессы. Использование служб позволяет ввести многослойную архитектуру, так же интегрировать несколько моделей, что вносит зависимость от инфраструктуры.
https://ru.wikipedia.org/wiki/Предметно-ориентированное_проектирование
-
MDD
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Разработка, управляемая моделями
Разработка, управляемая моделями, (англ. model-driven development) — это стиль разработки программного обеспечения, когда модели становятся основными артефактами разработки, из которых генерируется код и другие артефакты[1].
Модель — это абстрактное описание программного обеспечения, которое скрывает информацию о некоторых аспектах с целью представления упрощенного описания остальных. Модель может быть исходным артефактом в разработке, если она фиксирует информацию в форме, пригодной для интерпретаций людьми и обработки инструментами. Модель определяет нотацию и метамодель. Нотация представляет собой совокупность графических элементов, которые применяются в модели и могут быть интерпретированы людьми. Метамодель описывает понятия используемые в модели и фиксирует информацию в виде метаданных, которые могут быть обработаны инструментами.
Модели описанные на предметно-ориентированном языке программирования могут быть использованы, как точки расширения каркасов.
Источник https://ru.wikipedia.org/wiki/Разработка,_управляемая_моделями
-
GRASP
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Каталог шаблонов
-
Информационный эксперт (Information Expert)
-
Создатель (Creator)
-
Контроллер (Controller)
-
Слабое (низкое) зацепление (Low Coupling)
-
Сильная (высокая) связность (High Cohesion)
-
Полиморфизм (Polymorphism)
-
Чистая выдумка (Pure Fabrication)
-
Перенаправление (Indirection)
-
Устойчивость к изменениям (Protected Variations)
-
Информационный эксперт (Information Expert)
Шаблон определяет базовый принцип распределения ответственностей. Обязанности должны быть назначены объекту, который владеет максимумом необходимой информации для выполнения обязанности. Такой объект называется информационным экспертом.
Этот шаблон — самый очевидный и важный из девяти. Если его не учесть — получится спагетти-код, в котором трудно разобраться.
Локализация же ответственностей, проводимая согласно шаблону:
Повышает: Инкапсуляцию; Простоту восприятия; Готовность компонентов к повторному использованию; Снижает: степень зацепления.- Создатель (Creator)
Проблема: Кто отвечает за создание объекта некоторого класса A?
Решение: Назначить классу B обязанность создавать объекты класса A, если класс B:
содержит(contains) или агрегирует(aggregate) объекты A; записывает(records) объекты A; активно использует объекты A; обладает данными для инициализации объектов AМожно сказать, что шаблон «Creator» — это интерпретация шаблона «Information Expert» (смотрите пункт № 1) в контексте создания объектов.
Большинство порождающих шаблонов проектирования так или иначе выводятся или опираются на шаблон «Creator».
-
Контроллер (Controller)
Отвечает за операции, запросы которых приходят от пользователя, и может выполнять сценарии одного или нескольких вариантов использования (например, создание и удаление); Не выполняет работу самостоятельно, а делегирует компетентным исполнителям; Может представлять собой: Систему в целом; Подсистему; Корневой объект; Устройство.
-
Слабое (низкое) зацепление (Low Coupling) Основная статья: Зацепление (программирование)
Зацепление — мера того, насколько взаимозависимы разные подпрограммы или модули[2].
Сильное зацепление рассматривается как серьёзный недостаток, поскольку затрудняет понимание логики модулей, их модификацию, автономное тестирование, а также переиспользование по отдельности. Слабое зацепление, напротив, является признаком хорошо структурированной и хорошо спроектированной системы.
- Сильная (высокая) связность (High Cohesion) Основная статья: Связность (программирование)
Связность — мера силы взаимосвязанности элементов внутри модуля; способ и степень, в которой задачи, выполняемые некоторым программным модулем, связаны друг с другом[2].
Сильная связность класса / модуля означает, что его элементы тесно связаны и сфокусированы.
Слабая (низкая) связность класса / модуля означает, что он не сфокусирован на одной цели, его элементы предназначены для слишком многих несвязанных обязанностей. Такой модуль трудно понять, использовать и поддерживать.
- Полиморфизм (Polymorphism) См. также: Полиморфизм (информатика)
Устройство и поведение системы:
Определяется данными; Задано полиморфными операциями её интерфейса.Пример: Адаптация коммерческой системы к многообразию систем учёта налогов может быть обеспечена через внешний интерфейс объектов-адаптеров (см. также: Шаблон «Адаптеры»).
- Чистая выдумка (Pure Fabrication)
Не относится к предметной области, но:
Уменьшает зацепление; Повышает связность; Упрощает повторное использование.«Pure Fabrication» отражает концепцию сервисов в модели предметно-ориентированного проектирования.
Пример задачи: Не используя средства класса «А», внести его объекты в базу данных.
Решение: Создать класс «Б» для записи объектов класса «А» (см. также: «Data Access Object»).
- Перенаправление (Indirection) См. также: Посредник (шаблон проектирования)
Слабое зацепление между элементами системы (и возможность повторного использования) обеспечивается назначением промежуточного объекта их посредником.
Пример: В архитектуре Model-View-Controller, контроллер (англ. controller) ослабляет зацепление данных (англ. model) с их представлением (англ. view).
- Устойчивость к изменениям (Protected Variations) Шаблон защищает элементы от изменения другими элементами (объектами или подсистемами) с помощью вынесения взаимодействия в фиксированный интерфейс, через который (и только через который) возможно взаимодействие между элементами. Поведение может варьироваться лишь через создание другой реализации интерфейса.
https://ru.wikipedia.org/wiki/GRASP https://habr.com/ru/articles/92570/
-
Императивное программирование
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Императи́вное программи́рование — парадигма программирования (стиль написания исходного кода компьютерной программы), для которой характерно следующее:
- в исходном коде программы записываются инструкции (команды);
- инструкции должны выполняться последовательно;
- данные, получаемые при выполнении предыдущих инструкций, могут читаться из памяти последующими инструкциями;
- данные, полученные при выполнении инструкции, могут записываться в память.
-
Функциональное программирование
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Функциона́льное программи́рование — парадигма программирования, в которой процесс вычисления трактуется как вычисление значений функций в математическом понимании последних (в отличие от функций как подпрограмм в процедурном программировании).
Противопоставляется парадигме императивного программирования, которая описывает процесс вычислений как последовательное изменение состояний (в значении, подобном таковому в теории автоматов). При необходимости, в функциональном программировании вся совокупность последовательных состояний вычислительного процесса представляется явным образом, например, как список.
https://ru.wikipedia.org/wiki/Функциональное_программирование
-
Структурное программирование
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Парадигма программирования, в основе которой лежит представление программы в виде иерархической структуры блоков.
-
Закон Деметры
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Объе́ктно ориенти́рованное программи́рование (сокр. ООП) — методология или стиль программирования на основе описания типов/моделей предметной области и их взаимодействия, представленных порождением из прототипов или как экземпляры классов, которые образуют иерархию наследования.
При создании программных систем использование принципов SOLID способствует созданию такой системы, которую будет легко поддерживать и расширять в течение долгого времени. Принципы SOLID — это руководства, которые также могут применяться во время работы над существующим программным обеспечением для его улучшения, например, для удаления «дурно пахнущего кода».
-
Понятия ООП
- Знаю: Может рассказать и объяснить все термины
- Понимаю: На лайвкодинге может написать код используя термины.
Термины:
- Класс
- Объект
- Интерфейс
- Поля данных/Своиства
- Методы
- Контроль доступа
-
Принципы ООП
- Джун: Может объяснить базовые принципы.
- Мидл: Разбирается в принципах ООП.
- Синьор: Может на лафкодинге показать пример принципов ООП.
Принципы:
- Абстракция
- Инкапсуляция
- Наследование (Делегация, Композиция, Агрегация)
- Полиморфизм
Знания на сеньора:
- Динамическое связывание методов
- Динамическое создание и уничтожение объектов
- Значительная глубина абстракции
- Наследование «размывает» код
- Инкапсуляция снижает скорость доступа к данным
https://ru.wikipedia.org/wiki/Объектно-ориентированное_программирование
-
SOLID - S
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Знаю - знаю определение Понимаю - привести пример и досконально объяснить суть.
https://ru.wikipedia.org/wiki/Принцип_единственной_ответственности
-
SOLID - O
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
-
SOLID - L
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
-
SOLID - I
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
-
SOLID - D
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
https://habr.com/ru/companies/dataart/articles/262817/
https://gist.github.com/zmts/802dc9c3510d79fd40f9dc38a12bccfc?permalink_comment_id=4823694
-
Cookie/Session
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
software development process or software development life cycle (SDLC)
https://ru.wikipedia.org/wiki/Процесс_разработки_программного_обеспечения
Design Patterns, описанные в книге "Банды четырех"
Шаблоны используемы в построении архитектуры
todo
https://ru.wikipedia.org/wiki/%D0%90%D0%BD%D1%82%D0%B8%D0%BF%D0%B0%D1%82%D1%82%D0%B5%D1%80%D0%BD
https://ru.wikipedia.org/wiki/%D0%90%D0%BD%D1%82%D0%B8%D0%BF%D0%B0%D1%82%D1%82%D0%B5%D1%80%D0%BD
https://ru.wikipedia.org/wiki/%D0%90%D0%BD%D1%82%D0%B8%D0%BF%D0%B0%D1%82%D1%82%D0%B5%D1%80%D0%BD
https://proglib.io/tests/proydi-test-na-znanie-algoritmov-i-struktur-dannyh
https://education.yandex.ru/handbook/algorithms https://apptractor.ru/info/articles/6-algoritmov-kotorye-dolzhen-znat-kazhdyy-razrabotchik.html https://codechick.io/tutorials/dsa/dsa-algorithm
-
Динамическое программирование
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Динамическое программирование — способ решения сложных задач путём разбиения их на более простые подзадачи. Он применим к задачам с оптимальной подструктурой, выглядящим как набор перекрывающихся подзадач, сложность которых чуть меньше исходной. В этом случае время вычислений, по сравнению с «наивными» методами, можно значительно сократить.
Ключевая идея в динамическом программировании достаточно проста. Как правило, чтобы решить поставленную задачу, требуется решить отдельные части задачи (подзадачи), после чего объединить решения подзадач в одно общее решение. Часто многие из этих подзадач одинаковы. Подход динамического программирования состоит в том, чтобы решить каждую подзадачу только один раз, сократив тем самым количество вычислений. Это особенно полезно в случаях, когда число повторяющихся подзадач экспоненциально велико.
Метод динамического программирования сверху — это простое запоминание результатов решения тех подзадач, которые могут повторно встретиться в дальнейшем. Динамическое программирование снизу включает в себя переформулирование сложной задачи в виде рекурсивной последовательности более простых подзадач.
-
Рекурсия
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Рекурсия – это когда функция вызывает сама себя(напрямую или через функцию посредника), как правило, с другими аргументами. Рекурсия помогает писать код более компактно и понятно, однако имеет оверхэд по памяти из-за необходимости хранить стек вызова. Для оптимизации можно переписать алгоритм используя циклы - любая рекурсия может быть переделана в цикл, как правило, вариант с циклом будет эффективнее. Также есть хвостовая рекурсия.
Хвостовая рекурсия — частный случай рекурсии, при котором любой рекурсивный вызов является последней операцией перед возвратом из функции. Подобный вид рекурсии примечателен тем, что может быть легко заменён на итерацию путём формальной и гарантированно корректной перестройки кода функции. Оптимизация хвостовой рекурсии путём преобразования её в плоскую итерацию реализована во многих оптимизирующих компиляторах. В некоторых функциональных языках программирования спецификация гарантирует обязательную оптимизацию хвостовой рекурсии.
-
Разделяй и властвуй
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Разделяй и властвуй(divide and conquer) — важная парадигма разработки алгоритмов, заключающаяся в рекурсивном разбиении решаемой задачи на две или более подзадачи того же типа, но меньшего размера, и комбинировании их решений для получения ответа к исходной задаче; разбиения выполняются до тех пор, пока все подзадачи не окажутся элементарными.
Типичный пример — алгоритм сортировки слиянием. Чтобы отсортировать массив чисел по возрастанию, он разбивается на две равные части, каждая сортируется, затем отсортированные части сливаются в одну. Эта процедура применяется к каждой из частей до тех пор, пока сортируемая часть массива содержит хотя бы два элемента (чтобы можно было её разбить на две части).
Алгоритм стоит из 3 шагов:
- Разделяй. Разделяем задачу на подзадачи с помощью рекурсии.
- Властвуй. Как только задачи станут достаточно малы — рекурсивно решаем.
- Объединяй. Объединяем все подзадачи в одно целое, чтобы получить решение исходной задачи.
-
Хэш-таблица (Hash Table)
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Структура данных, основанная на хэш-функции, которая преобразует ключ в индекс массива для хранения значения.
Преимущества:
- Быстрый доступ, вставка и удаление элементов (в среднем O(1))
- Гибкость структуры
Недостатки:
- Возможность коллизий хэш-функции
- Затраты памяти на хранение элементов и обработку коллизий
Применение:
- Хэш-таблицы используются в поисковых алгоритмах, кэшировании данных, реализации ассоциативных массивов и словарей.
-
Стэк(Stack)
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Cтруктура данных, организованная по принципу "последний пришел, первый ушел" (LIFO). Элементы добавляются и удаляются с одного конца структуры.
Преимущества:
- Простота реализации
- Легкость использования в рекурсии и отката операций
Недостатки:
- Ограниченный доступ к элементам (только к вершине стека)
Применение:
- Стеки полезны при выполнении рекурсивных функций, обработке скобочных последовательностей и отмене операций.
-
Очередь (Queue)
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Структура данных, организованная по принципу "первый пришел, первый ушел" (FIFO). Элементы добавляются в конец очереди и удаляются из начала.
Преимущества:
- Поддержка естественного порядка обработки элементов
- Применение в алгоритмах обхода и поиска
Недостатки:
- Ограниченный доступ к элементам (только к началу и концу очереди)
Применение:
- Очереди используются в алгоритмах обхода в ширину, приоритетных очередях и многопоточных приложениях для обработки задач.
Виды:
- Простая очередь
- Круговая очередь
- Очередь с приоритетом
- Двухсторонняя очередь https://codechick.io/tutorials/dsa/dsa-queue
-
Связанный список (Linked List)
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Связанный список - это структура данных, состоящая из узлов, каждый из которых содержит значение элемента и указатель на следующий узел в списке.
Существуют односвязные списки, где каждый узел имеет указатель только на следующий узел, двусвязные списки, где узлы имеют указатели на предыдущий и следующий узлы и кольцевые.
Преимущества:
- Динамическое изменение размера списка (в отличие от массивов)
- Эффективное добавление и удаление элементов в начале или конце списка
- Относительно простая реализация
Недостатки:
- Непостоянное время доступа к элементам (в отличие от массивов)
- Больший объем занимаемой памяти по сравнению с массивами из-за хранения указателей на узлы
Применение:
- Связанные списки подходят для реализации стеков, очередей, а также для задач, где требуется частое добавление или удаление элементов и не требуется быстрый доступ к элементам по индексу.
-
Граф (Graph)
- Джун: Начальные/Поверхностные знания.
- Мидл: Средние знания. Можете объяснить суть и есть опыт применения..
- Сеньор: Продвинутые знания. Можете показать на примере, знаете нюансы и можете научить.
Структура данных, состоящая из вершин (узлов) и ребер, которые соединяют эти вершины. Графы могут быть ориентированными (направленными) или неориентированными.
Преимущества:
- Отражение сложных отношений между элементами
- Гибкость структуры
Недостатки:
- Сложность реализации и обработки
- Большие затраты памяти
Применение:
- в транспортных сетях
- социальных сетях
- веб-технологиях
- задачи оптимизации
-
Куча (Heap)
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Куча (структура данных) — это полное двоичное дерево, удовлетворяющее свойству кучи: если узел A — это родитель узла B, то ключ узла A ≥ ключ узла B.
- Если любой узел всегда больше дочернего узла (узлов), а ключ корневого узла является наибольшим среди всех остальных узлов, это max-куча.
- Если любой узел всегда меньше дочернего узла (узлов), а ключ корневого узла является наименьшим среди всех остальных узлов, это min-куча.
-
Битовые поля (Bit Arrays)
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Битовые поля (Bit Arrays), где каждый бит представляет элемент данных. Часто используются для оптимизации использования памяти, когда нужно хранить множество флагов или булевых значений.
-
Массивы (Arrays)
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Массивы – это простейшая структура данных, представляющая собой набор элементов одного типа, расположенных последовательно в памяти. Хранит набор значений (элементов массива), идентифицируемых по индексу или набору индексов, принимающих целые (или приводимые к целым) значения из некоторого заданного непрерывного диапазона.
Преимущества:
Быстрый доступ к элементам по индексу Непрерывная область памятиНедостатки:
Фиксированный размер Неэффективное добавление/удаление элементовПрименение: Массивы подходят для хранения набора данных с фиксированным размером, где операции вставки и удаления элементов не требуются.
-
Двоичное дерево
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Двоичное дерево — древовидная структура данных, в которой у родительских узлов не может быть больше двух детей.
Типы двоичных деревьев
- Полное двоичное дерево — особый тип бинарных деревьев, в котором у каждого узла либо 0 потомков, либо 2.
- Совершенное двоичное дерево — особый тип бинарного дерева, в котором у каждого внутреннего узла по два ребенка, а листовые вершины находятся на одном уровне.
- Законченное двоичное дерево похоже на совершенное, но есть три большие отличия.
- Все уровни должны быть заполнены.
- Все листовые вершины склоняются влево.
- У последней листовой вершины может не быть правого собрата. Это значит, что завершенное дерево необязательно полное.
- Вырожденное двоичное дерево — дерево, в котором на каждый уровень приходится по одной вершине.
- Скошенное вырожденное дерево — вырожденное дерево, в котором есть либо только левые, либо только правые узлы. Таким образом, есть два типа скошенных деревьев — скошенные влево вырожденные деревья и скошенные вправо вырожденные деревья.
- Сбалансированное двоичное дерево — тип бинарного дерева, в котором у каждой вершины количество вершин в левом и правом поддереве различаются либо на 0, либо на 1.
-
Дерево двоичного поиска
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Дерево двоичного поиска — это структура данных, которая позволяет быстро работать с отсортированном списком чисел.
Дерево двоичное, потому что у каждого узла не более двух дочерних элементов.
Дерево поиска, потому что его можно использовать для проверки вхождения числа — за время O(log(n)).
Чем отличается от обычного двоичного дерева
Все узлы левого поддерева меньше корневого узла. Все узлы правого поддерева больше корневого узла. Оба поддерева каждого узла тоже являются деревьями двоичного поиска, т. е. также обладают первыми двумя свойствами.У правого дерева есть поддерево со значением 2, которое меньше, чем корень 3 — таким дерево двоичного поиска быть не может.
-
B-дерево
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
B-дерево (читается как Би-дерево) — это особый тип сбалансированного дерева поиска, в котором каждый узел может содержать более одного ключа и иметь более двух дочерних элементов. Из-за этого свойства B-дерево называют сильноветвящимся.
Зачем нужно
Вторичные запоминающие устройства (жесткие диски, SSD) медленно работают с большим объемом данных. Людям захотелось сократить время доступа к физическим носителям информации, поэтому возникла потребность в таких структурах данных, которые способны это сделать.
Двоичное дерево поиска, АВЛ-дерево, красно-черное дерево и т. д. могут хранить только один ключ в одном узле. Если нужно хранить больше, высота деревьев резко начинает расти, из-за этого время доступа сильно увеличивается.
С B-деревом все не так. Оно позволяет хранить много ключей в одном узле и при этом может ссылаться на несколько дочерних узлов. Это значительно уменьшает высоту дерева и, соответственно, обеспечивает более быстрый доступ к диску.
Свойства
- Ключи в каждом узле x упорядочены по неубыванию.
- В каждом узле есть логическое значение x.leaf. Оно истинно, если x — лист.
- Каждый узел, кроме корня, содержит не менее t-1 ключей, а каждый внутренний узел имеет как минимум t дочерних узлов, где t — минимальная степень B-дерева.
- Все листья находятся на одном уровне, т. е. обладают одинаковой глубиной, равной высоте дерева.
- Корень имеет не менее 2 дочерних элементов и содержит не менее 1 ключа.
-
R-дерево
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
R-дерево (R-trees) — древовидная структура данных (дерево). Она подобна B-дереву, но используется для организации доступа к пространственным данным, то есть для индексации многомерной информации, такой, например, как географические данные с двумерными координатами (широтой и долготой). Типичным запросом с использованием R-деревьев мог бы быть такой: «Найти все музеи в пределах 2 километров от моего текущего местоположения».
Эта структура данных разбивает многомерное пространство на множество иерархически вложенных и, возможно, пересекающихся, прямоугольников (для двумерного пространства). В случае трехмерного или многомерного пространства это будут прямоугольные параллелепипеды (кубоиды) или параллелотопы.
Алгоритмы вставки и удаления используют эти ограничивающие прямоугольники для обеспечения того, чтобы «близкорасположенные» объекты были помещены в одну листовую вершину. В частности, новый объект попадёт в ту листовую вершину, для которой потребуется наименьшее расширение её ограничивающего прямоугольника. Каждый элемент листовой вершины хранит два поля данных: способ идентификации данных, описывающих объект, (либо сами эти данные) и ограничивающий прямоугольник этого объекта.
Аналогично, алгоритмы поиска (например, пересечение, включение, окрестности) используют ограничивающие прямоугольники для принятия решения о необходимости поиска в дочерней вершине. Таким образом, большинство вершин никогда не затрагиваются в ходе поиска. Как и в случае с B-деревьями, это свойство R-деревьев обусловливает их применимость для баз данных, где вершины могут выгружаться на диск по мере необходимости.
Для расщепления переполненных вершин могут применяться различные алгоритмы, что порождает деление R-деревьев на подтипы: квадратичные и линейные.
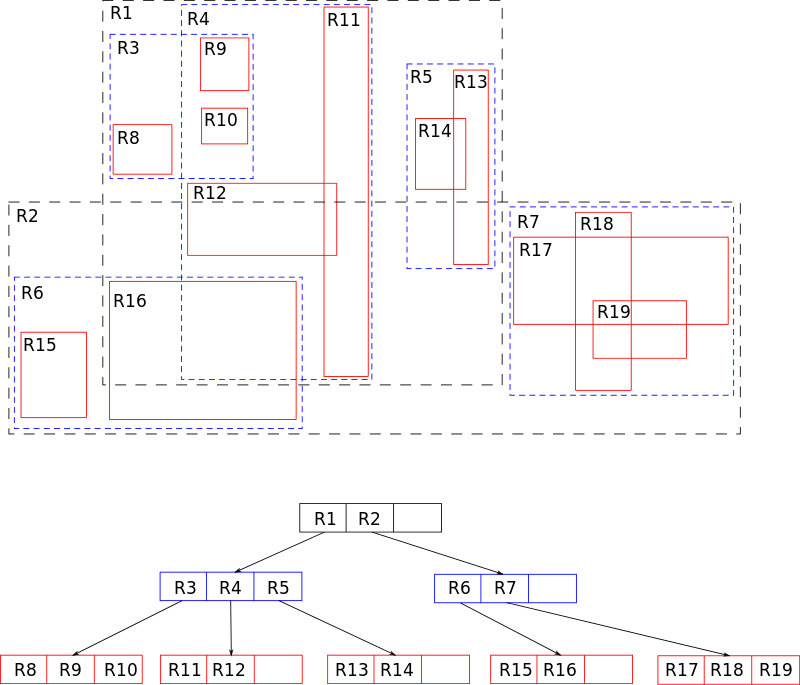
Структура R-дерева
Каждая вершина R-дерева имеет переменное количество элементов (не более некоторого заранее заданного максимума). Каждый элемент нелистовой вершины хранит два поля данных: способ идентификации дочерней вершины и ограничивающий прямоугольник (кубоид), охватывающий все элементы этой дочерней вершины. Все хранимые кортежи хранятся на одном уровне глубины, таким образом, дерево идеально сбалансировано. При проектировании R-дерева нужно задать некоторые константы:
MaxEntries — максимальное число детей у вершины MinEntries — минимальное число детей у вершины, за исключением корня.Для корректной работы алгоритмов необходимо выполнение условия MinEntries <= MaxEntries / 2. В корневой вершине может быть от 2 до MaxEntries потомков. Часто выбирают MinEntries = 2, тогда для корня выполняются те же условия, что и для остальных вершин. Также иногда разумно выделять отдельные константы для количества точек в листовых вершинах, так как их часто можно делать больше.
-
Сортировка пузырьком / Bubble sort
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Или сортировка простыми обменами. Обходим массив от начала до конца, попутно меняя местами неотсортированные соседние элементы. В результате первого прохода на последнее место «всплывёт» максимальный элемент. Теперь снова обходим неотсортированную часть массива (от первого элемента до предпоследнего) и меняем по пути неотсортированных соседей. Второй по величине элемент окажется на предпоследнем месте. Если за проход не произошло ни одного обмена, то массив отсортирован. Продолжая в том же духе, будем обходить всё уменьшающуюся неотсортированную часть массива, запихивая найденные максимумы в конец. Очевидно, не более чем после n итераций массив будет отсортирован.
-
Сортировка вставками / Insertion sort
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Элементы входной последовательности просматриваются по одному, и каждый новый поступивший элемент размещается в подходящее место среди ранее упорядоченных элементов.
-
Сортировка выбором / Selection sort
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
На очередной итерации будем находить минимум в массиве после текущего элемента и менять его с ним, если надо. Таким образом, после i-ой итерации первые i элементов будут стоять на своих местах. Нужно отметить, что эту сортировку можно реализовать двумя способами – сохраняя минимум и его индекс или просто переставляя текущий элемент с рассматриваемым, если они стоят в неправильном порядке.
-
Быстрая сортировка / Quicksort
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Выбрать из массива элемент, называемый опорным(pivot). Это может быть любой из элементов массива. От выбора опорного элемента не зависит корректность алгоритма, но в отдельных случаях может сильно зависеть его эффективность. В ранних реализациях, как правило, опорным выбирался первый элемент, что снижало производительность на отсортированных массивах. Для улучшения эффективности может выбираться средний, случайный элемент или (для больших массивов) медиана первого, среднего и последнего элементов. Медиана всей последовательности является оптимальным опорным элементом, но её вычисление слишком трудоёмко для использования в сортировке. Сравнить все остальные элементы с опорным и переставить их в массиве так, чтобы разбить массив на три непрерывных отрезка, следующих друг за другом: «элементы меньшие опорного», «равные» и «большие». На практике массив обычно делят не на три, а на две части: например, «меньшие опорного» и «равные и большие»; такой подход в общем случае эффективнее, так как упрощает алгоритм разделения Для отрезков «меньших» и «больших» значений выполнить рекурсивно ту же последовательность операций, если длина отрезка больше единицы.
-
Сортировка слиянием / Merge sort
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Сортировка, основанная на парадигме «разделяй и властвуй». Разделим массив пополам, рекурсивно отсортируем части, после чего выполним процедуру слияния: поддерживаем два указателя, один на текущий элемент первой части, второй – на текущий элемент второй части. Из этих двух элементов выбираем минимальный, вставляем в ответ и сдвигаем указатель, соответствующий минимуму. Слияние работает за O(n), уровней всего logn, поэтому асимптотика O(n logn). Эффективно заранее создать временный массив и передать его в качестве аргумента функции. Эта сортировка рекурсивна, как и быстрая, а потому возможен переход на квадратичную при небольшом числе элементов.
-
Сортировка кучей
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
ßКуча (heap) — это не что иное, как двоичное дерево с некоторыми дополнительными правилами, которым оно должно следовать: во-первых, оно всегда должно иметь структуру кучи, где все уровни двоичного дерева заполняются слева направо, и, во-вторых, оно должно быть упорядочено в виде max-кучи или min-кучи. В качестве примера я буду использовать min-кучу.
Алгоритм пирамидальной сортировки — это метод сортировки, который полагается на такие структуры данных как двоичные кучи. Поскольку мы знаем, что кучи всегда должны соответствовать определенным требованиям, мы можем использовать это для поиска элемента с наименьшим значением, последовательно сортируя элементы, выбирая корневой узел кучи и добавляя его в конец массива.
Работает в худшем, в среднем и в лучшем случае (то есть гарантированно) за O(n*log n) операций при сортировке n элементов. Количество применяемой служебной памяти не зависит от размера массива O(1). Может рассматриваться как усовершенствованная сортировка пузырьком, в которой элемент всплывает/тонет по многим путям.
https://backendinterview.ru/algostruct/graph.html https://backendinterview.ru/algostruct/index.html
-
Двоичный (бинарный) поиск
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Также известен как метод деления пополам или дихотомия — классический алгоритм поиска элемента в отсортированном массиве (векторе), использующий дробление массива на половины.
Ищет элемент в отсортированном массиве:
Определение значения элемента в середине структуры данных. Полученное значение сравнивается с ключом. Если ключ меньше значения середины, то поиск осуществляется в первой половине элементов, иначе — во второй. Поиск сводится к тому, что вновь определяется значение серединного элемента в выбранной половине и сравнивается с ключом. Процесс продолжается до тех пор, пока не будет найден элемент со значением ключа или не станет пустым интервал для поиска. -
Троичный (Тернарный) поиск
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Трои́чный по́иск (Тернарный поиск) — это метод в информатике для поиска максимумов и минимумов функции, которая либо сначала строго возрастает, затем строго убывает, либо наоборот. Троичный поиск определяет, что минимум или максимум не может лежать либо в первой, либо в последней трети области, и затем повторяет поиск на оставшихся двух третях. Троичный поиск демонстрирует парадигму программирования «разделяй и властвуй».
/** Находит максимум функции с одним экстремумом между l и r. Чтобы найти минимум - достаточно поменять местами действия в ветках if/else. */ double l = ..., r = ..., EPS = ...; // входные данные double m1, m2; while (r - l > EPS) { m1 = l + (r - l) / 3; m2 = r - (r - l) / 3; if (f (m1) < f (m2)) l = m1; else r = m2; } -
Поиск в ширину (BFS)
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Поиск в ширину(Breadth-First Search, BFS) — это один из основных алгоритмов на графах. В результате поиска в ширину находится путь кратчайшей длины в невзвешенном графе, т.е. путь, содержащий наименьшее число рёбер. Например, если мы ищем на карте метро путь от Сокольников, до Парка Победы, содержащий наименьшее число станций, то мы ищем в ширину.
BFS следует концепции «расширяйся, поднимаясь на высоту птичьего полета» («go wide, bird’s eye-view»). Вместо того чтобы двигаться по определенному пути до конца, BFS предполагает движение вперед по одному соседу за раз.
-
Поиск в глубину (DFS)
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Поиск в глубину(Depth-First Search, DFS) находит такой путь от данной вершины, до нужной, что этот путь содержит минимальную сумму ребер графа. Например, если мы ищем на карте метро путь от Сокольников, до Парка Победы, требующий наименьшее время для переезда(расстояние между каждыми соседними станциями, будет весом ребра), то мы ищем в глубину.
DFS следует концепции «погружайся глубже, головой вперед» («go deep, head first»). Идея заключается в том, что мы двигаемся от начальной вершины (точки, места) в определенном направлении (по определенному пути) до тех пор, пока не достигнем конца пути или пункта назначения (искомой вершины). Если мы достигли конца пути, но он не является пунктом назначения, то мы возвращаемся назад (к точке разветвления или расхождения путей) и идем по другому маршруту.
-
Алгори́тм Де́йкстры
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Алгори́тм Де́йкстры (Dijkstra’s algorithm) — алгоритм на графах, изобретённый нидерландским учёным Эдсгером Дейкстрой в 1959 году. Находит кратчайшие пути от одной из вершин графа до всех остальных. Алгоритм работает только для графов без рёбер отрицательного веса.
Каждой вершине из V сопоставим метку — минимальное известное расстояние от этой вершины до a. Алгоритм работает пошагово — на каждом шаге он «посещает» одну вершину и пытается уменьшать метки. Работа алгоритма завершается, когда все вершины посещены.
Инициализация. Метка самой вершины a полагается равной 0, метки остальных вершин — бесконечности. Это отражает то, что расстояния от a до других вершин пока неизвестны. Все вершины графа помечаются как не посещённые.
Шаг алгоритма. Если все вершины посещены, алгоритм завершается. В противном случае из ещё не посещённых вершин выбирается вершина u, имеющая минимальную метку. Мы рассматриваем всевозможные маршруты, в которых u является предпоследним пунктом. Вершины, в которые ведут рёбра из u, назовём соседями этой вершины. Для каждого соседа вершины u, кроме отмеченных как посещённые, рассмотрим новую длину пути, равную сумме значений текущей метки u и длины ребра, соединяющего u с этим соседом. Если полученное значение длины меньше значения метки соседа, заменим значение метки полученным значением длины. Рассмотрев всех соседей, пометим вершину u как посещённую и повторим шаг алгоритма.
-
Алгоритм Флойда (алгоритм Флойда–Уоршелла)
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Алгоритм нахождения длин кратчайших путей между всеми парами вершин во взвешенном ориентированном графе. Работает корректно, если в графе нет циклов отрицательной величины, а в случае, когда такой цикл есть, позволяет найти хотя бы один такой цикл. Алгоритм работает за Θ(n3) времени и использует Θ(n2) памяти.
-
Задача о рюкзаке
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Задача о рюкзаке (также задача о ранце) — NP-полная задача комбинаторной оптимизации. Своё название получила от конечной цели: уложить как можно большее число ценных вещей в рюкзак при условии, что вместимость рюкзака ограничена. С различными вариациями задачи о рюкзаке можно столкнуться в экономике, прикладной математике, криптографии и логистике.
В общем виде задачу можно сформулировать так: из заданного множества предметов со свойствами «стоимость» и «вес» требуется отобрать подмножество с максимальной полной стоимостью, соблюдая при этом ограничение на суммарный вес.
https://habr.com/ru/companies/otus/articles/770248/ https://habr.com/ru/companies/otus/articles/782064/ https://habr.com/ru/companies/ruvds/articles/732648/
Криптогра́фия — наука о методах обеспечения конфиденциальности (невозможности прочтения информации посторонним), целостности данных (невозможности незаметного изменения информации), аутентификации (проверки подлинности авторства или иных свойств объекта), а также невозможности отказа от авторства.
https://habr.com/ru/articles/549054/ https://habr.com/ru/articles/587620/ https://xbsoftware.ru/blog/metodologii-testirovaniya-po-kakuyu-vybrat/
-
Приемочное тестирование
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Приемочное тестирование
-
Тестирование производительности
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Тестирование производительности
-
AB-тесты
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
AB-тесты
Технологии используемые в разработке для развертывания и деплоя
https://habr.com/ru/articles/258443/ https://kubernetes.io/ru/docs/concepts/overview/what-is-kubernetes/
- Сервисы метрик и логирования
-
Git
- Джун: Начальные/Поверхностные знания.
- Мидл: Средние знания. Можете объяснить суть и есть опыт применения..
- Сеньор: Продвинутые знания. Можете показать на примере, знаете нюансы и можете научить.
Git — распределённая система управления версиями.
Базы данны SQL, NoSQL и сервисы очередей
-
Виды отношений таблиц
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
- один к одному
- один ко многим
- многие к одному
- многие ко многим
-
Репликация
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
- Блочная репликация - При блочной репликации каждая операция записи выполняется не только на основном диске, но и на резервном. Таким образом тому на одном массиве соответствует зеркальный том на другом массиве, с точностью до байта повторяющий основной том
- Физическая репликация - Журналы (redo log или write-ahead log) содержат все изменения, которые вносятся в файлы базы данных. Идея физической репликации состоит в том, что изменения из журналов повторно выполняются в другой базе (реплике), и таким образом данные в реплике повторяют данные в основной базе байт-в-байт.
- Логическая репликация - Все изменения в базе данных происходят в результате вызовов её API – например, в результате выполнения SQL-запросов.
- Репликация триггерами - риггер – хранимая процедура, которая исполняется автоматически при каком-либо действии по модификации данных.
- Прикладная репликация - формирование векторов изменений непосредственно на стороне клиента. Клиент должен формировать детерминированные запросы, затрагивающие единственную запись.
https://ru.wikipedia.org/wiki/Репликация_(вычислительная_техника)
-
Шардирование
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Виды:
- Вертикальное
- Горизонтальное
Методы шардинга:
- Хешированное
- Диапазонное
- Круговое
- Динамическое
https://yandex.cloud/ru/docs/glossary/sharding?utm_referrer=https%3A%2F%2Fwww.google.com%2F
-
Партицирование
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Партиционирование — это разбиение таблиц, содержащих большое количество записей, на логические части по неким выбранным администратором критериям. Партиционирование таблиц делит весь объем операций по обработке данных на несколько независимых и параллельно выполняющихся потоков, что существенно ускоряет работу СУБД. Для правильного конфигурирования параметров партиционирования необходимо, чтобы в каждом потоке было примерно одинаковое количество записей.
- горизонтальное партицирование
- вертикальное партицирование
- функциональное партицирование
-
Внешний ключ
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Foreign key Внешние ключи позволяют установить связи между таблицами. Внешний ключ устанавливается для столбцов из зависимой, подчиненной таблицы, и указывает на один из столбцов из главной таблицы. Как правило, внешний ключ указывает на первичный ключ из связанной главной таблицы.
https://ru.wikipedia.org/wiki/Внешний_ключ https://metanit.com/sql/mysql/2.5.php
-
Join
- Джун: Начальные/Поверхностные знания.
- Мидл: Средние знания. Можете объяснить суть и есть опыт применения..
- Сеньор: Продвинутые знания. Можете показать на примере, знаете нюансы и можете научить.
- left
- right
- inner
- outer
-
Нормальная форма
- Джун: Начальные/Поверхностные знания.
- Мидл: Средние знания. Можете объяснить суть и есть опыт применения..
- Сеньор: Продвинутые знания. Можете показать на примере, знаете нюансы и можете научить.
- Первая НФ
- Вторая НФ
- Третья НФ
- Четвертая НФ
- Пятая НФ
- Шестая НФ
- денормализация
Транзакционные базы данных (базы, работающие через транзакции) выполняют требования ACID, которые обеспечивают безопасность данных.
https://habr.com/ru/articles/537594/ https://ru.wikipedia.org/wiki/Транзакция_(информатика)
-
Движки таблиц
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
- MyIsam
- InnoDb
- Memory
- ...
-
Типы индексов
- Джун: Начальные/Поверхностные знания.
- Мидл: Средние знания. Можете объяснить суть и есть опыт применения..
- Сеньор: Продвинутые знания. Можете показать на примере, знаете нюансы и можете научить.
-
R-Tree (Пространственный индекс) https://ru.wikipedia.org/wiki/R-дерево_(структура_данных)
-
Hash index
-
Inverted index
-
Уникальный индекс (Unique Index)
-
Полнотекстовый индекс (Full-Text Index)
-
Составной индекс
-
Кластеризованные
-
некластеризованные
https://timeweb.cloud/tutorials/sql/indeksy-v-sql-sozdanie-vidy-i-kak-rabotayut https://www.mysql.ru/docs/man/MySQL_indexes.html https://habr.com/ru/articles/556440/
https://habr.com/ru/companies/tensor/articles/779698/ https://habr.com/ru/articles/340460/
Знания языка программирования PHP
-
Типы данных PHP
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
- Атомарные
- Составные
- Пересечение
- Объединение
- Псевдонимы
https://www.php.net/manual/ru/language.types.type-system.php
-
Магические методы
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
-
Static/Self/parent
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
https://www.php.net/manual/ru/language.oop5.late-static-bindings.php https://www.php.net/manual/ru/language.oop5.static.php
-
Генераторы/Итераторы
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
https://www.php.net/manual/ru/language.generators.overview.php https://www.php.net/manual/ru/language.oop5.iterations.php https://www.php.net/manual/ru/class.iterator.php
-
Трейты
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
l
-
Fibers
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
https://www.php.net/manual/ru/class.fiber.php https://habr.com/ru/articles/756642/ https://habr.com/ru/articles/756642/
-
Reflection
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
-
Исключения
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
- Встроенные классы исключений.
- Try/Catch/Finally
- Стрелочные функции
- Тернарный оператор
-
Анонимны/Лямбда функции
- Использую: Знаю что это и как ими пользоваться
- Продвинутые знания: Понимаю особенности.
-
Атрибуты
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
-
Ковариантность и контравариантность
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
-
Opcode/Opcache/JIT
- Джун: Начальные/Поверхностные знания.
- Мидл: Средние знания. Можете объяснить суть и есть опыт применения..
- Сеньор: Продвинутые знания. Можете показать на примере, знаете нюансы и можете научить.
-
PDO
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
-
xDebug
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
-
Обработка ошибок
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
- errorclearlast
- errorgetlast
- error_log
- error_reporting
- seterrorhandler
- restoreerrorhandler
- setexceptionhandler
- restoreexceptionhandler
- trigger_error
- user_error
-
Паралельнные процессы
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
PHP vendors
Навыки связанные с client-side разработкой
-
Минификация
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Cжатие js/css кода для ускорения загрузки
https://sky.pro/wiki/javascript/minimizaciya-i-obuedinenie-css-i-js/
-
Code Splitting
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Разделение кода на пакеты, чтоб загружать его по мере необходимости.
Применяется совместно с Lazy Loading
-
Lazy Loading
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Загрузка кода по частям по мере необходимости.
Применяется совместно с Code Splitting
-
Tree Shaking
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Удаление не используемого кода.
https://sky.pro/wiki/javascript/tree-shaking-v-javascript-kak-umenshit-razmer-bandla/
-
Форматы изображений
- Знакомо: Имею общее представление о большинстве форматах
- Знаю: Знаю плюсы и минусы основных форматов jpg, png, gif, svg, ico
- Понимаю: Понимаю и могу объяснить как устроены алгоритмы сжатия в различных форматах.
Растровые и векторные форматы изображений (jpg, png, gif, svg, ico, tiff, avif, apng, hiec, webp, bmp, raw и т.д.).
Оптимизация и особенности применения.
-
SVG
- Знаю: Базовый синтаксис и принцип работы
- Понимаю и применяю: Могу поменять текст, сформировать новое изображение с нуля, анимировать графику
-
Оптимизация загрузки ресурсов
- Джун: Начальные/Поверхностные знания.
- Мидл: Средние знания. Можете объяснить суть и есть опыт применения..
- Сеньор: Продвинутые знания. Можете показать на примере, знаете нюансы и можете научить.
способы подключения ресурсов (async/defer, prefetch/preload)
Preload, prefetch и другие теги https://habr.com/ru/articles/445264/
Разница между async и defer у тега script https://wp-kama.ru/id_12151/raznitsa-async-defer.html
Как быстрее DOM построить: парсинг, async, defer и preload https://habr.com/ru/articles/338840/
-
CDN
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Хранение статики
-
Service Worker
- Джун: Начальные/Поверхностные знания.
- Мидл: Средние знания. Можете объяснить суть и есть опыт применения..
- Сеньор: Продвинутые знания. Можете показать на примере, знаете нюансы и можете научить.
Основное назначение - Push уведомления, фоновая синхронизация и кэшерование.
https://developer.mozilla.org/ru/docs/Web/API/Service_Worker_API/Using_Service_Workers
https://learn.javascript.ru/first-steps https://habr.com/ru/companies/ruvds/articles/416375/
-
.call и .apply
- Знаю: Знаю что это, читал/изучал.
разница между .call и .apply
-
cookie, sessionStorage и localStorage
- Джун: Начальные/Поверхностные знания.
- Мидл: Средние знания. Можете объяснить суть и есть опыт применения..
- Сеньор: Продвинутые знания. Можете показать на примере, знаете нюансы и можете научить.
Разница и ограничения cookie, sessionStorage и localStorage.
https://learn.javascript.ru/localstorage?ysclid=m4f9fptrr1171420958
-
let, var и const
- Знаю: Знаю что это, читал/изучал.
Разница между let, var и const
-
Обработка ошибок и исключений
- Знаю: Знаю что это, читал/изучал.
Обработка ошибок и исключений
-
Promise
- Джун: Начальные/Поверхностные знания.
- Мидл: Средние знания. Можете объяснить суть и есть опыт применения..
- Сеньор: Продвинутые знания. Можете показать на примере, знаете нюансы и можете научить.
-
Fetch
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
https://developer.mozilla.org/en-US/docs/Web/API/Fetch_API/Using_Fetch
-
NaN
- Знаю: Знаю что это, читал/изучал.
Что такое и особенности NaN
-
Event loop
- Знаю: Знаю что это, читал/изучал.
Event loop
-
Сypress
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Фреймворк для автоматизированного тестирования
https://docs.cypress.io/app/get-started/why-cypress https://habr.com/ru/companies/otus/articles/672098/
https://habr.com/ru/companies/piter/articles/820027/ https://habr.com/ru/companies/macloud/articles/559902/
https://itanddigital.ru/bloghrconsulting/tpost/o9gce6b1b1-50-osnovnih-voprosov-i-otvetov-na-sobese
Webpack — это модульный сборщик (bundler) с открытым исходным кодом, написанный на JavaScript.
Он берёт несколько скриптов JavaScript с их зависимостями и объединяет в файл, который используется браузером.
Преимущества Webpack:
ускоряет разработку, убирая необходимость постоянно перезагружать веб-страницу при изменениях в JS-файлах;
обеспечивает разделение кода на отдельные модули, которые можно переиспользовать внутри веб-приложения;
позволяет избежать проблем с перезаписью глобальных переменных;
поддерживает минификацию, то есть сокращение объёма кода без изменения его функциональности;
умеет работать с разными спецификациями модулей.-
Gulp
- Джун: Начальные/Поверхностные знания.
- Мидл: Средние знания. Можете объяснить суть и есть опыт применения..
- Сеньор: Продвинутые знания. Можете показать на примере, знаете нюансы и можете научить.
Gulp
-
Семантическая верстка
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
-
Псевдо-классы
- Знаю: Знаю что это, читал/изучал.
псевдо-классы
-
Нормализаця стилей
- Знаю: Знаю что это, читал/изучал.
нормализаця стилей
-
Медиазапросы
- Знаю: Знаю что это, читал/изучал.
Медиазапросы
-
animation,transition,transform
- Знаю: Знаю что это, читал/изучал.
animation,transition,transform
-
Псевдо-элементы
- Знаю: Знаю что это, читал/изучал.
Псевдо-элементы
::after, ::before
-
Селекторы и приоритеты стилей
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
CSS фреймворки
-
LESS
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
LESS
-
SASS
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
SASS
-
БЭМ
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
БЭМ
-
Bootstrap
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Bootstrap
-
UIKit
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
UIKit
Навыки по разработке приложений для Android
Навыки по разработке приложений на iOS, для iPhone , iMac
https://help.ubuntu.com/kubuntu/desktopguide/ru/linux-basics.html https://habr.com/ru/articles/655275/
Сетевые протоколы (IP, Transport, etc)
-
TCP/IP
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
TCP/IP
-
UDP
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
UDP
-
HTTP/HTTPS
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
HTTP/HTTPS
-
IMAP/POP3
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
IMAP/POP3
-
TLS
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
TLS
-
DNS
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
DNS
-
Сетевая безопасность
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
- DDOS
- XSS
-
Сетевая модель OSI
- Джун: Начальные/Поверхностные знания.
- Мидл: Средние знания. Можете объяснить суть и есть опыт применения..
- Сеньор: Продвинутые знания. Можете показать на примере, знаете нюансы и можете научить.
Сетевая модель OSI (The Open Systems Interconnection model) — сетевая модель стека (магазина) сетевых протоколов OSI/ISO. Посредством данной модели различные сетевые устройства могут взаимодействовать друг с другом. Модель определяет различные уровни взаимодействия систем. Каждый уровень выполняет определённые функции при таком взаимодействии.
Soft skills
-
Таим менеджмент
- Базовые понятия: Умеете планировать свою жизнь и дела на 1-2 дня, есть абстрактные цели.
- Применяете методики: Знаете что такое VUCA, BANI или другой метод и используете его. Планируете свои дела на каждую неделю. Ставите цели минимум на 1 год. Переодический проводите ретроспективу и корректировку долгосрочных планов.
- Управляете временем: Время работает на вас. Вы наставник или можете быть им.
https://practicum.yandex.ru/blog/taym-menedzhment-kak-upravlyat-vremenem/
https://trends.rbc.ru/trends/education/606335659a7947a191c4b092
-
Самостоятельность
- Джун: Проактивно предупреждает о потенциальных проблемах, запрашивает помощь и так далее. Способен предоставлять отчет по задаче, когда спрашивают
- Мидл: Способен самостоятельно ставить себе задачи на протяжении длительного времени, занимаясь только согласованием видения с "архитекторами" и "владельцами продукта"
- Синьор: Имеет четкое понимание приоритетов задач с точки зрения разработки. Прислушивается к приоритетам с точки зрения бизнеса, способен обеспечить "героические" усилия (деливери в ограниченные сроки) не путем сверхусилий команды, а путем совместного упрощения задач и т.п.
-
Менторство
- Джун: Способен отвечать на вопросы по проекту / технологиям. Способен делиться своими знаниями, в формате "здесь надо делать не так"
- Мидл: Способен эффективно обучать небольшую группу сотрудников. Составлять план развития.
- Синьор: Способен доносить знания неопределённо широкому кругу людей. Владеет навыками психологии-педагогики-групповой динамики для максимально эффективного менторинга
https://blog.karpachoff.com/kommunikativnye-navyki-kak-ih-razvit-i-uluchshit
-
Инициатор
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Иницирует коммуникации по мере возникновения проблем в текущих задачахи и в рамках действующих регламентов (стэндапы, ретроспективы и т.д.)
-
Аргументирование
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Способен оппонировать другим разработчикам, в том числе и вышестоящим, если уверен в своих аргументах. Отслеживает результаты коммуникаций в контексте конкретных действий
-
Эффективность
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Применяет инженерный подход в общении - коммуникации используются как эффективный инструмент достижения целей. В рабочих процессах полностью отсутсвуют коммуникации, которые не способствуют достижению конкретных целей
-
Эмоциональный интеллект
- Начальный уровень: Знаете все понемногу.
- Средний: У вас полностью прокачен навык "Самосознание".
- Высокий: Высокий уровень навыка "Самоконтроль" и "Эмпатия"
- Продвинутый: В полной мере владеете всеми навыками.
Это обширный навык который включает себя несколько других навыков:
- Самосознание: Восприятие эмоций. Способность осознавать и анализировать собственные эмоции, а также знание своих слабых и сильных сторон.
- Самоконтроль: Умение управлять своими эмоциями и сохранять эмоциональный баланс даже в критических ситуациях.
- Эмпатия: Понимание эмоций окружающих и способность общаться с другими с учетом их внутреннего состояния.
- Навыки отношений: Умение взаимодействовать с людьми, управлять их эмоциями, улаживать конфликты, работать в команде или возглавлять ее.
https://presium.pro/blog/what-is-emotional-intelligence https://journal.tinkoff.ru/emotional-intelligence/
-
Коммуникации
- Начальный уровень: Способность эффективно слушать и понимать других участников коммуникации, ясное и понятное выражение своих мыслей и идей, умение задавать вопросы и запрашивать уточнения для полного понимания задач и требований.
- Средний уровень: Грамотное и уверенное выступление перед аудиторией различного уровня сложности, адаптация к различным коммуникационным стилям и предпочтениям участников коммуникации, навыки убеждения и влияния на принятие решений и согласование с разными заинтересованными сторонами, способность конструктивно обрабатывать фидбэк и критику.
- Высокий уровень: Эффективное управление конфликтами и разрешение спорных ситуаций в коммуникации, умение адаптировать свой стиль коммуникации к разным культурным контекстам и международным командам, умение вести эффективные совещания и встречи, учитывая потребности и цели всех участников.
Устная, письменна, и чтение.
- Английский
Методы достижения целей
-
SMART
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
подход к постановке целей, который помогает выбрать формулировку желаемого результата, дает чувство направления и помогает организовать и достичь целей.
-
GROW
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
-
Метод Брайана Трэйси
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Метод Брайана Трэйси
-
Метод Марка Аллена
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Метод Марка Аллена
Бизнес-анализ
-
Планирование
- Знаю: Знаю что это, читал/изучал.
- Понимаю: Понимаю (знаю достоинства и недостатки) и был опыт применения.
Планирование